
Spring Webflux 찍먹해보기
Reactive Programming의 배경
리액티브 프로그래밍이 나오게된 배경으로는 크게 두가지 문제를 해결하기 위함이다.
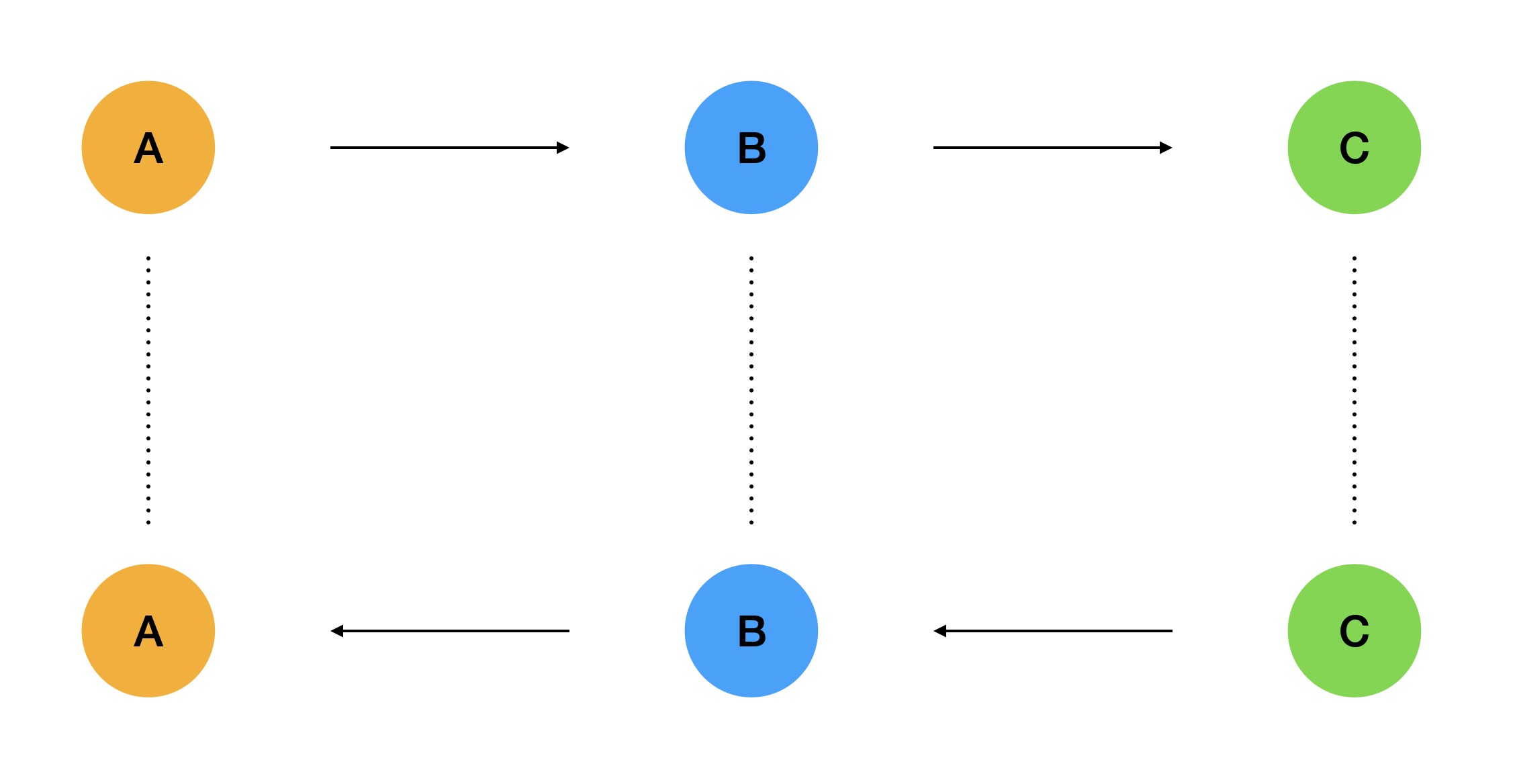
쉽게 표현하자면 이렇게 표현할 수 있다.
- 멍 때리는 시간이 많다. (-> 시간을 줄일 수 있게)
- 물어봐야만 알 수 있다. (-> 안물어봐도 알 수 있게)
첫 번째 문제부터 이야기해보자면, 리액티브 프로그래밍이 나오기전 일반적인 프로그래밍 방식으로는
하나의 요청이 왔을때 요청을 받은 스레드는 응답할때까지 다른 요청을 받지 못하게 된다.
응답할때 까지 다른 요청을 받지 못하는 상황을 쉽게 멍 때린다라고 표현하겠다.
스레드가 멍때리고 있는동안은 다른 요청을 받지 못하게 되는데, 이러한 내용은 C10K 에서 여러 해결방안이 나왔다.
일반적으로는 이런 상황을 해결하기 위해서 새로운 스레드를 할당해서 새로운 요청을 받게 한다.
하지만 일반적으로 tomcat의 스레드풀에 스레드는 약 200개가 세팅되는데 동시에 약 200개의 요청이 들어온다면 결과를 보장할 수 없게 된다.
또한 스레드를 무한정 늘리기는 불가능하고 컨텍스트 스위칭 비용이 상당하다.
두 번째 문제는 클라이언트에서 서버에 무언가를 질의해야만 클라이언트에 응답을 할 수 있다는 것이다.
클라이언트-서버 구조에서는 클라이언트에서 요청을 해야만 서버가 응답할 수 있는데, 이 구조에서 문제는
서버에 리소스가 부족할때 요청이 와도 응답을 해야하고, 반대로 리소스가 넉넉할때 요청이 오지 않으면 응답할 수 없다는 문제를 갖고있다.
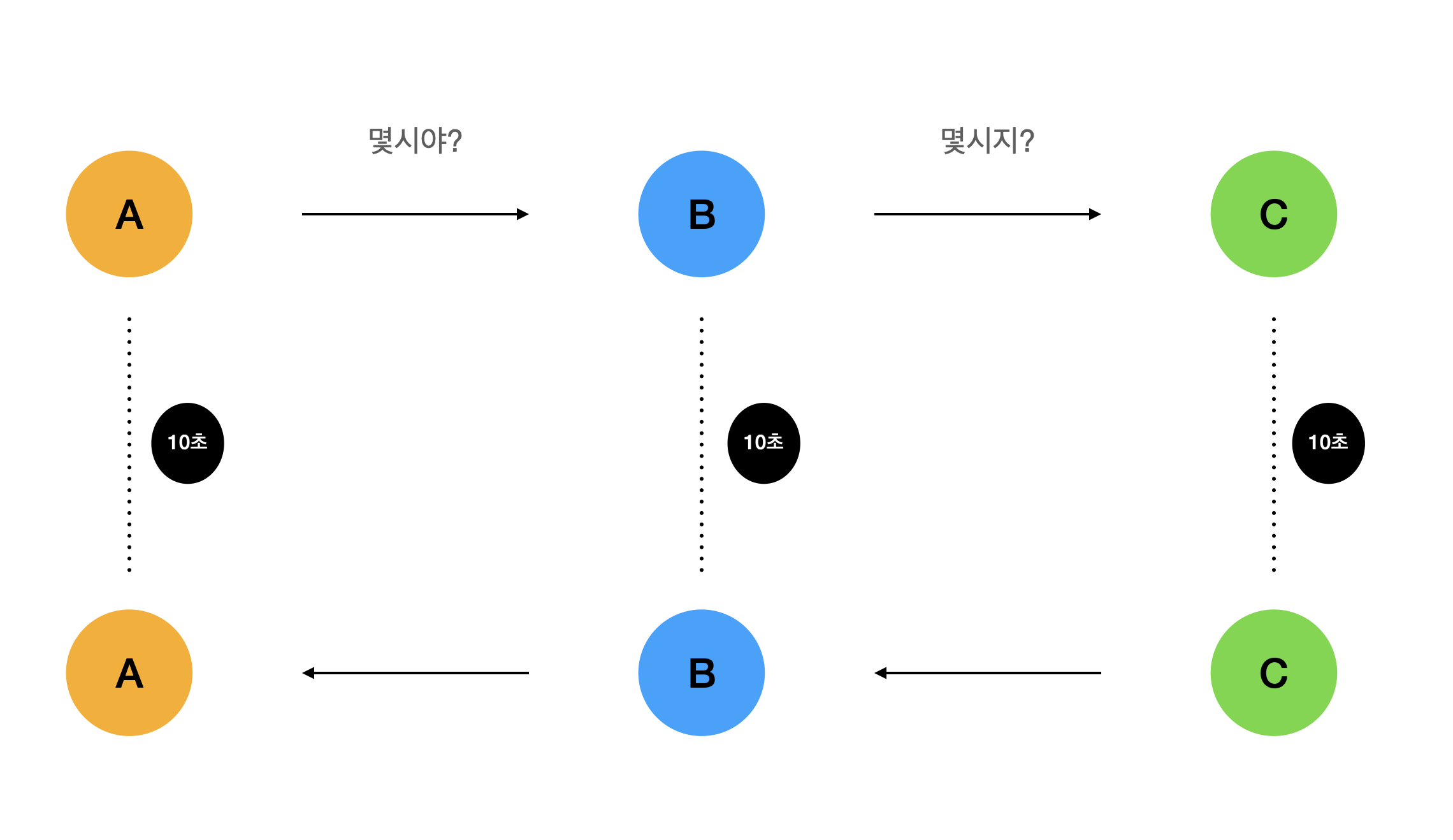
위 두 문제를 해결하기위해 리액티브 프로그래밍은 두 가지 해결책을 제시했다.
첫 번째 문제인 멍 때리는 시간은 이벤트 루프를 도입해 해결하고자 했고,
두 번째 문제는 응답을 유지하는 Stream을 도입하여 지속적인 응답을 하여 해결 했다.
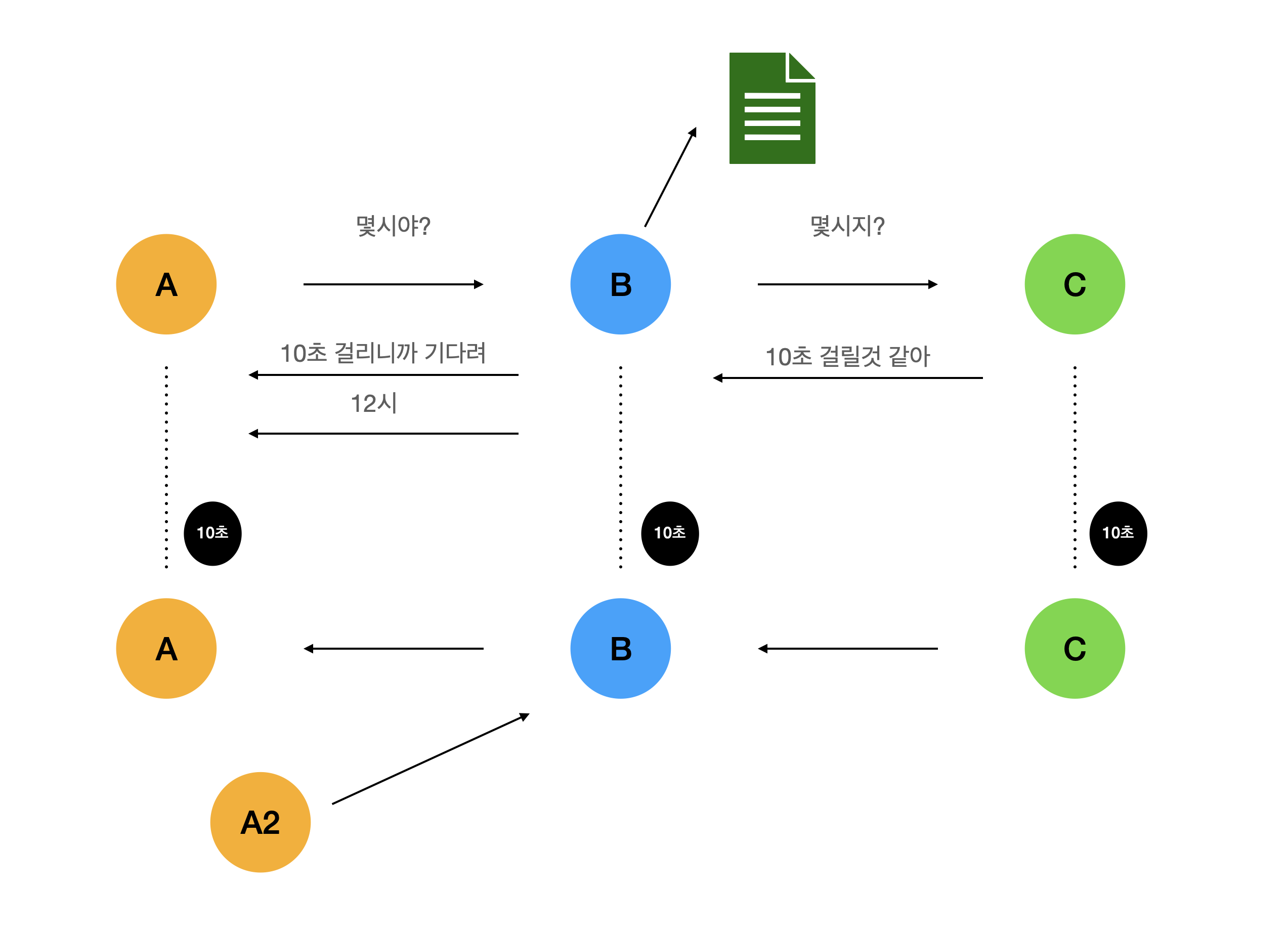
그리고 이 두 해결책을 Spring Web에 적용한게 Spring Webflux 이다.
다시말해 Spring Webflux(Project Reactor)는 Reactive Streams 라는 라이브러리를 기반으로한 구현체라고 볼 수 있다.
Reactive Streams API
Spring Webflux를 알기 전에 Reactive Streams는 어떻게 생겼을까라는 궁금증이 생길 수 있다.
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}
public interface Subscription {
public void request(long n);
public void cancel();
}
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {
}
Reactive Streams API는 4개의 인터페이스를 갖고있으며 간단하게 생겼다.
- Project Reactor
- RxJava
- Akka Streams
- Java9
인터페이스를 구현한 구현체로는 위와 같은 프로젝트들이 있고 Spring Webflux는 그 중 Project Reactor를 사용했다고 보면 된다.
Spring boot2는 Reactive Stack 그리고 우리가 잘 아는 Servelet Stack을 제공한다.
동시에 사용할 수는 없고 한가지를 선택해야한다.

Spring MVC (Servelet Stack)
다시 처음으로 돌아가서 Servelet Stack을 사용할때의 문제점을 다시 파악해보자
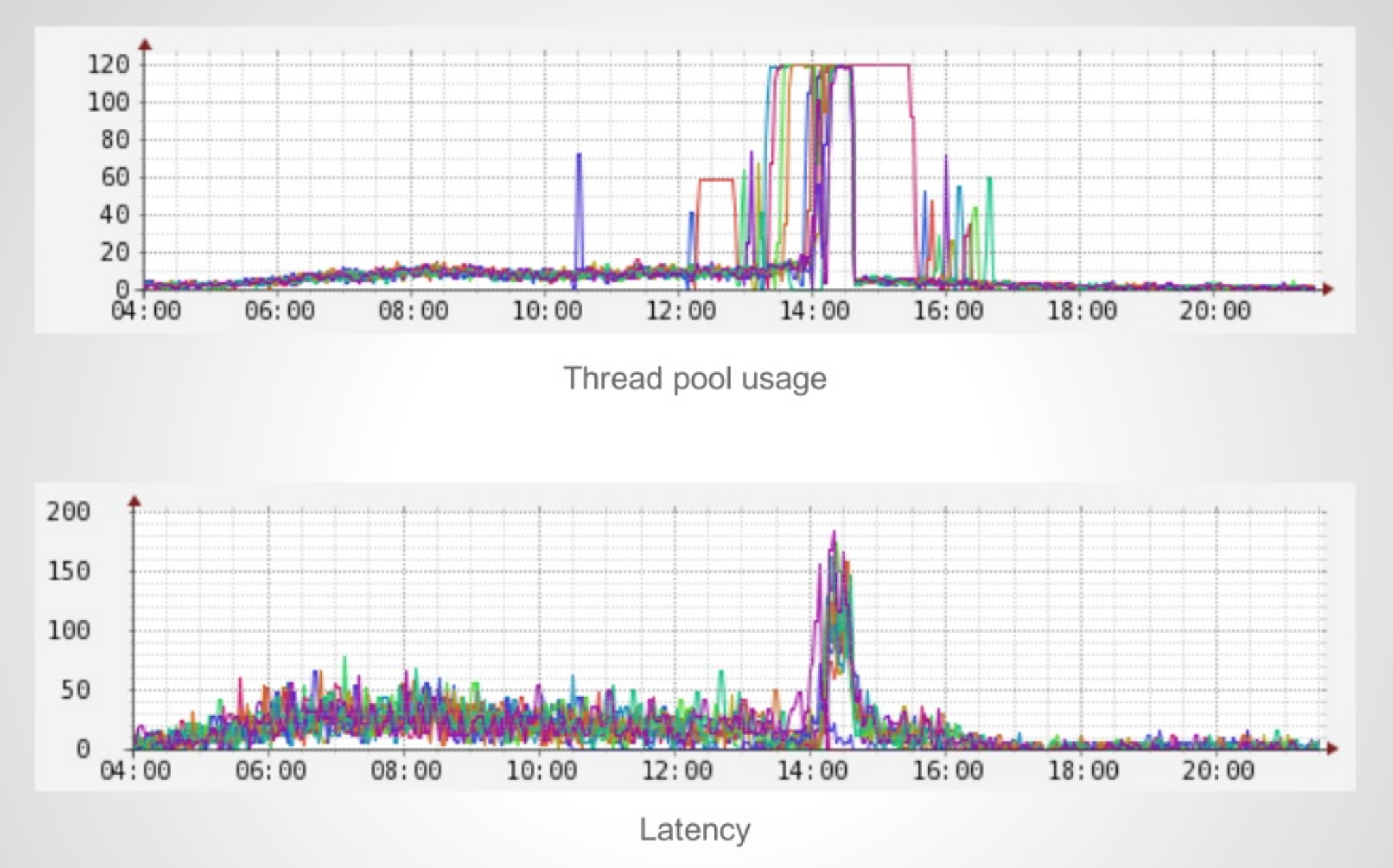
Servelet Stack을 사용할 경우 기본적으로 스레드풀에 스레드는 200개가 할당된다.
1대1로 요청과 스레드가 매칭되는 구조인데 동시에 200개가 넘는 요청을 받기 위해 요청들을 Queue에 담게 된다
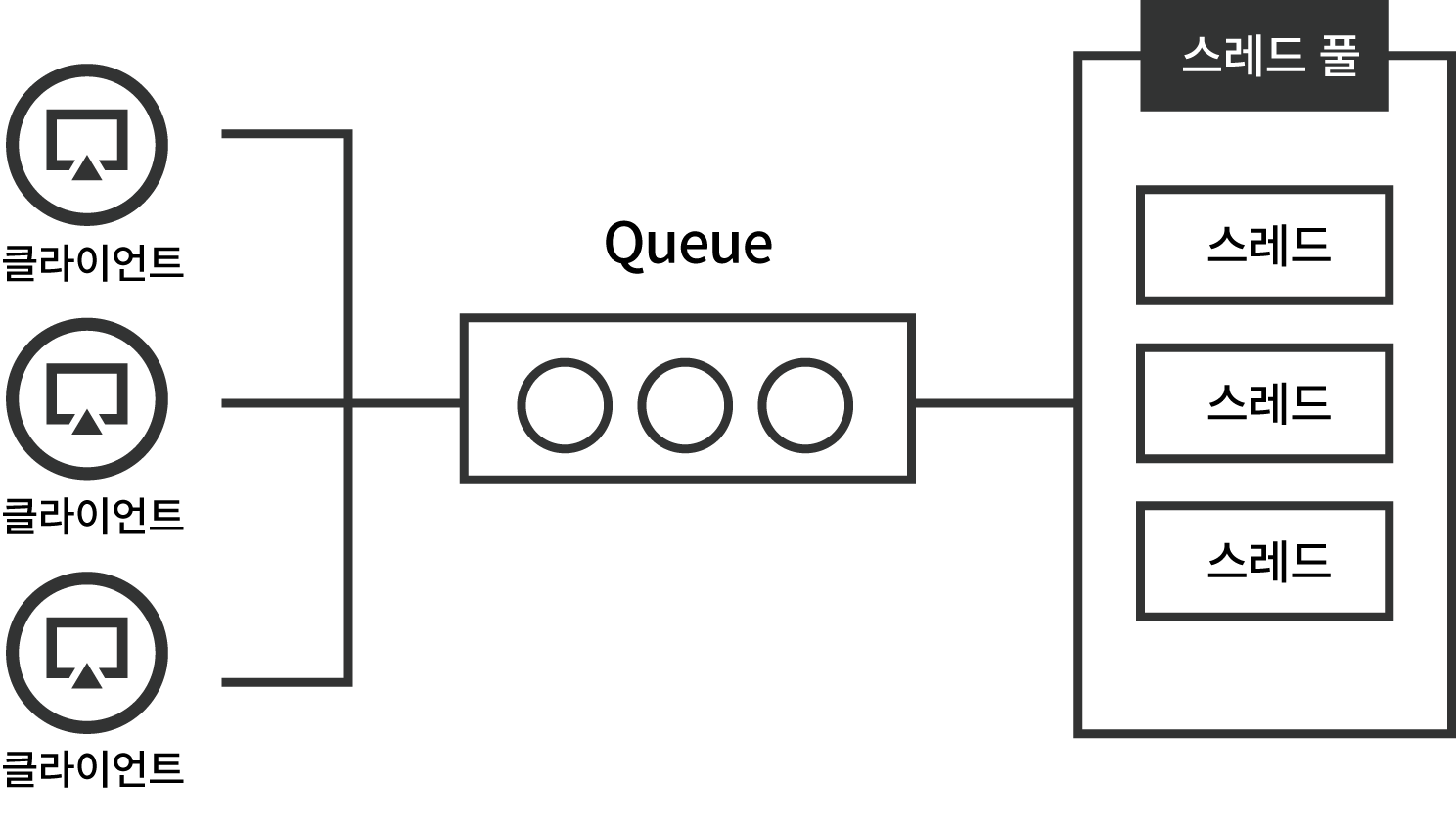
그림처럼 HTTP 요청들은 먼저 큐에 담기게 되고 순차적으로 스레드풀에서 스레드를 할당받아 요청이 처리된다
스레드풀은 스레드를 동적으로 생성하는 비용이 크기 때문에 스레드를 서버 성능에 맞게 미리 최대치를 생성해두고 풀에 두어 재사용한다
하지만 설정해둔 스레드가 모두 할당되어 새로운 요청을 처리하지 못한다면 큐에 대기중이던 요청들이 모두 Hang에 걸리게되고
전체 응답시간이 늘어나게 되며, 이것을 Thread pool hell 이라고 부른다
Spring Webflux (Reactive Stack)
Reactive stack을 사용하게되면 요청마다 스레드를 할당하는 방식이 아닌 Event Loop 을 통해 요청이 처리된다.
Servelet Stack과 다르게 이벤트 루프는 싱글스레드 기반이기 때문에 적은 수의 스레드로도 다수의 요청을 처리할 수 있다.
이 방식은 이미 Javascript 진영에서는 오래전부터 사용되는 방식이고 특히 Node.js에는 동일한 방식으로 많은 구현 사례를 볼 수 있다.
이벤트 루프는 서버의 코어 수 만큼 메인 스레드를 할당하고 요청이 들어온다면 메인 스레드가 이벤트 루프에 요청을 등록하고
워커 스레드가 이벤트 루프에 쌓여있는 요청들을 처리하게 된다.
요즈음 많이 사용되고 있는 MSA 아키텍처에서 서로가 수 많은 네트워크 호출을 하게 되는데 이럴 경우 Network I/O를 더 효율적으로 처리할 수 있게 된다.
하지만 이 방식은 I/O 작업이 모두 논 블로킹 방식으로 작성이 되어야 한다.
즉 CPU boundary 와 같은 블로킹 방식으로 작성된 코드가 있다면 의미가 없어지게 된다.
예를들어 처리할 수 있는 메인 스레드가 2개이고 4명이 동시에 요청을 했을때를 가정한다면
내부에 무한 반복문과 같은 블로킹 되는 Cpu Boundary 코드가 있게 된다면 이벤트 루프에 요청을 등록하지 못하고
응답을 못하게 되기 때문에 남은 2개의 요청은 무한 반복문이 끝날때 까지 기다릴 수 밖에 없게 된다.
이러한 단점 외에도 트래킹이 어렵다는 단점이 있고, 우리가 일반적으로 사용하는 JPA는 Reactive Stack에 적합하지 않다는 점이 있다.
JPA는 비동기를 지원하지 않기 때문에 최근에 공개된 R2DBC 또는 Reactive Mongo와 같은 라이브러리를 사용해야 된다.
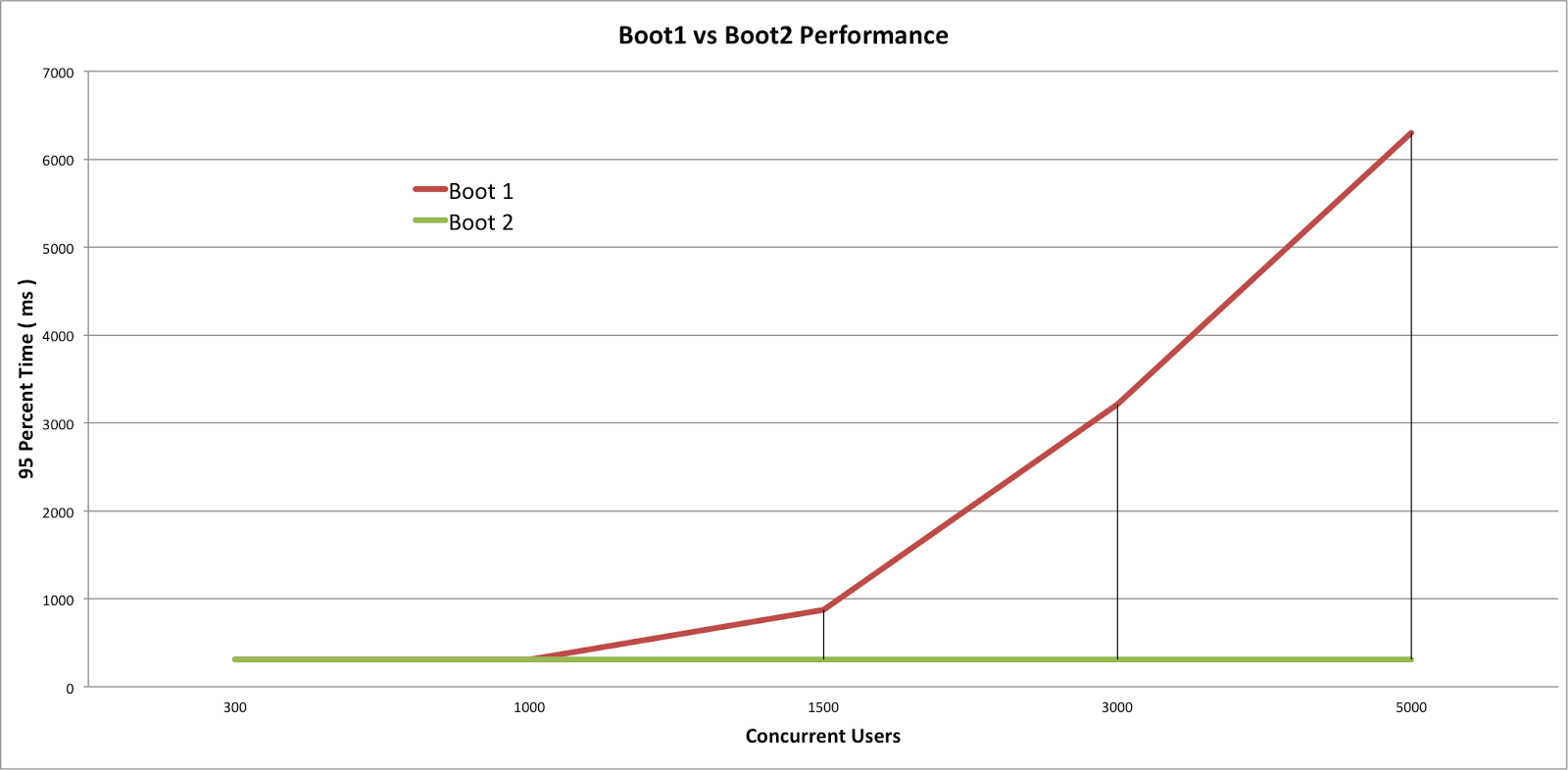
그렇다면 언제 Webflux를 사용해야할까?
적은 수의 스레드로 많은 요청을 처리할 수 있으니 무조건 Webflux를 써야하는것은 아니다
왜냐하면 위의 표를 보면 알 수 있듯이 어느정도 요청까지는 Webflux나 MVC 둘 다 크게 차이가 없다
그리고 MVC가 개발하기에 더 용이하기 때문에 생산성 또한 더 높다고 볼 수 있다.
요즘은 서버 장비의 공급이 많아지고 가격이 낮아지는 추세기 때문에 리소스가 부족하다면 Scale up, scale out을 하여
확장하며 문제를 해결하는게 더 효율적일 수 있다.
Webflux는 한정된 장비에서 극한의 효율을 추구하거나 또는 정말 I/O에 특화된 서비스에 적용하면 좋을것 같다
참고
- https://hyunsoori.tistory.com/3
- https://alwayspr.tistory.com/44