
트랜잭션에 대하여
이번에 공부하게 된 트랜잭션에 대해 정리를 해본다.
먼저 미래의 나를 믿지 못하기에 미리 트랜잭션이 무엇인지 간단히 정의를 하고 넘어 가기로 하겠다.
트랜잭션?
트랜잭션(Transaction 이하 트랜잭션)이란, 데이터베이스의 상태를 변화시키기 해서 수행하는 작업의 단위를 뜻한다.
데이터베이스의 상태를 변화시킨다는 것은 무얼 의미하는 것일까?
간단하게 말해서 아래의 질의어(SQL)를 이용하여 데이터베이스를 접근 하는 것을 의미한다.
SELECT, INSERT, DELETE, UPDATE
착각하지 말아야 할 것은, 작업의 단위는 질의어 한문장이 아니라는 점이다.
작업단위는 많은 질의어 명령문들을 사람이 정하는 기준에 따라 정하는 것을 의미한다.
트랜잭션 특징
트랜잭션의 특징은 크게 4가지로 구분된다.
-
Atomicity(원자성): 이체 과정 중에 트랜잭션이 실패하게 되어 예금이 사라지는 경우가 발생해서는 안 되기 때문에 DBMS는 완료되지 않은 트랜잭션의 중간 상태를 데이터베이스에 반영해서는 안 된다. 즉, 트랜잭션의 모든 연산들이 정상적으로 수행 완료되거나 아니면 전혀 어떠한 연산도 수행되지 않은 상태를 보장해야 한다. atomicity는 쉽게 ‘all or nothing’ 특성으로 설명된다.
-
Consistency(일관성): 고립된 트랜잭션의 수행이 데이터베이스의 일관성을 보존해야 한다. 즉, 성공적으로 수행된 트랜잭션은 정당한 데이터들만을 데이터베이스에 반영해야 한다. 트랜잭션의 수행을 데이터베이스 상태 간의 전이(transition)로 봤을 때, 트랜잭션 수행 전후의 데이터베이스 상태는 각각 일관성이 보장되는 서로 다른 상태가 된다. 트랜잭션 수행이 보존해야 할 일관성은 기본 키, 외래 키 제약과 같은 명시적인 무결성 제약 조건들뿐만 아니라, 자금 이체 예에서 두 계좌 잔고의 합은 이체 전후가 같아야 한다는 사항과 같은 비명시적인 일관성 조건들도 있다.
-
Isolation(독립성): 여러 트랜잭션이 동시에 수행되더라도 각각의 트랜잭션은 다른 트랜잭션의 수행에 영향을 받지 않고 독립적으로 수행되어야 한다. 즉, 한 트랜잭션의 중간 결과가 다른 트랜잭션에게는 숨겨져야 한다는 의미인데, 이러한 isolation 성질이 보장되지 않으면 트랜잭션이 원래 상태로 되돌아갈 수 없게 된다. Isolation 성질을 보장할 수 있는 가장 쉬운 방법은 모든 트랜잭션을 순차적으로 수행하는 것이다. 하지만 병렬적 수행의 장점을 얻기 위해서 DBMS는 병렬적으로 수행하면서도 일렬(serial) 수행과 같은 결과를 보장할 수 있는 방식을 제공하고 있다.
-
Durability(지속성): 트랜잭션이 성공적으로 완료되어 커밋되고 나면, 해당 트랜잭션에 의한 모든 변경은 향후에 어떤 소프트웨어나 하드웨어 장애가 발생되더라도 보존되어야 한다.
학교에서 디비 수업을 듣지 못한 나도 들어본 ACID
로컬 트랜잭션과 글로벌 트랜잭션
로컬 트랜잭션
- 로컬 트랜잭션은 아래와 같이 흐름으로 나타낸다.
- begin -> commit
- commit 이 곧 end와 prepare를 모두 포함하고 있다고 보면 된다. 참고로 1PC는 대부분 로컬 트랜잭션으로 처리할 수 있다. 같은 리소스 내에서 일어나는 독립적인 일들을 하나로 묶으면 로컬 트랜잭션이 되는 것이다. 또한 로컬 트랜잭션은 같은 리소스 내에서 일을 하면 된다는 가정이 있기 때문에 기본적으로 일 처리가 빠르다.
글로벌 트랜잭션
- 글로벌 트랜잭션은 트랜잭션에 참여한 여러 독립적인 일들 중 하나라도 다른 리소스에서 일어나는 경우다. 앞서 2PC의 예에서 설명한 것처럼 서로 다른 은행 간에 이체를 해야 하다면 이는 글로벌 트랜잭션이다. 그리고 글로벌 트랜잭션을 하려면 반드시 2PC를 해야만 한다. 글로벌 트랜잭션은 여러 리소스 사이에서 처리하는 작업이기 때문에 ‘분산’ 트랜잭션(Distributed Transaction)이라고도 하며 이를 줄여서 XA 라고 부른다. XA는 이전 글에서 설명한 2PC 알고리즘을 기반으로 하고 있다.
한 가지 주의할 점은 1PC는 글로벌 트랜잭션이라는 것이다. 글로벌 트랜잭션에 참여한 일들이 전부 같은 리소스에서 하는 일이라서 <준비> 작업을 안 해도 되겠다고 판단하는 것이지, 갑자기 로컬 트랜잭션으로 바꿔서 진행하는 것이 아니다. 정리하면 1PC는 글로벌 트랜잭션 최적화(Global Transaction Optimization) 알고리즘들 중의 하나이다.
그렇다면 로컬 트랜잭션을 최적화(Optimization)하는 알고리즘은 없는가? 답은 단순하다. 없다. 단지 로컬 트랜잭션을 이용해서 글로벌 트랜잭션을 최적화 하는 알고리즘이 있다.
분산 데이터베이스 트랜잭션
네트워크로 물린 여러 데이터베이스가 참여 한다.
A의 데이터는 A-a 라는 디비에 있고, B의 데이터는 B-b 라는 디비에 있다면
거래를 하면서 돈이 없어지거나 복사되지 않는 다는 보장을 어떻게 보장 해야할까?
- 해결 방안 1 - XA
- 커밋할 준비(무결성 확인)와 실제 커밋(디스크에 쓰기)을 분리
- DB가 여럿일 때에도 고립성을 확보해준다.
- 문제점
- 장애 상황(서버 다운)에서 원자성을 보장하지 않는다.
- 느림
- 해결 방안 2 - 직접 만든다 ( 애플리케이션 레벨 분산 트랜잭션 )
로컬 트랜잭션을 여러번 실행해서 분산 트랜잭션을 구현한다.
하지만 물품 거래를 예로 들면 A의 트랜잭션 (물품 제거, 잔액 증가) 과 B의 트랜잭션(잔액 감소, 물품 추가)사이에서
갑자기 B의 디비서버가 꺼진다면 트랜잭션의 무결성을 보장할 수 없게 된다.
이러한 문제점을 보완하기 위해서는 두가지 접근 방법이 있다.
- 작업하는 동안 다른 동작을 하게 한다
- 비관적 동기화 ( 락 기반 동기화 )
- 일단 진행하고, 문제가 생기면 롤백한다
- 낙관적 동기화 ( 예/ 트랜잭셔널 메모리 )
비관적 동기화의 문제점은 모든 디비 변경에서 락을 잡아야하고
작업하는 동안 다른 동작을 못하게 할 수 없는 현상이 있다 ( 서버 다운 )
낙관적 동기화의 문제점은 애플리케이션 레벨에서 롤백을 구현해야 한다는 점이다.
애플리케이션 레벨에서의 트랜잭션을 구현하기 우ㅟ해서는 두 단계로 나눌 수 있다.
- 퍼스트 로컬 트랜잭션 ( FLT )
- 실패할 가능성이 있는 것
- 안전하게 롤백할 수 있어야 한다. (롤백 해야 된다.)
- 예/ 물품 제거, 잔액 감소
- 세컨드 로컬 트랜잭션 ( SLT )
- 실패할 가능성이 없는 것
- 안전하게 롤백할 수 없어도 된다. (롤백 안해도 된다.)
- 예/ 물품 추가, 잔액 증가
절차를 보자면
- 모든 디비에게 FLT 실행
- 거래 대상이 되는 재산을 가압류 한다.
- 모든 FLT가 성공하고 나면 SLT를 실행한다.
- 모든 디비의 재산을 가압류 성공하면 거래를 마저 진행할 수 있다.
- 만일 FLT가 하나라도 실패하면 전부 롤백한다.
- 가압류를 풀고 없던일로 한다.
구현의 문제점 1
- 물품의 경우
- 물품 테이블에 ‘거래 중’ 컬럼을 추가해야 하는지
- ‘거래 중’ 테이블을 따로 추가 해야하는지?!
- 돈
- 가압류된 돈의 컬럼을 추가해야하나?
구현의 문제점 2
- 서버가 트랜잭션 하다가 다운된다면, 다른 곳에서 트랜잭션을 이어서 진행행야한다. ( 롤백 또는 SLT를 모두 수행해야 한다 )
- 개별 트랜잭션 마다 복구 코드를 작성해야 한다.
해결 방안
- 롤백할 때 해야 할 일과, SLT할 때 해야할 일을 SQL 쿼리 텍스트로 만들어
- 각 DB의 FLT 시점에 기록한다.
SQL 쿼리 텍스트를 이용 하는 이유
- 어떤 응용에서도 변하지 않는 부분 = 시스템 코드
- 예/ FLT중 하나라도 실패하면 롤백하는 규칙, 중단된 분산 트랜잭셔녀이 있으면 이어서 실행해주는 코드
- 응용에 따라 변하는 부분 = 로직 코드
- 예/ 카드 거래, 쿠푠 사용 등등
시스템 코드와 로직 코드를 분리 해야 하기 때문이다.
로직 코드는 각각의 디비에 대해서
- 빼거나 감소해야할 자원을 처리한다 = FLT
- FLT를 롤백할 때 행야 할 일을 SQL로 기록해 둔다.
- 넘겨주기로 한 재산을 가압류 하는 컨셉
- 거래가 취소되면 가압류를 푼다 -> 롤백 쿼리 실행.
- 거래중에는 내가 함부로 처분 못한다 -> 실제 행을 지웠기 때문에
- SLT를 해야 할 때 해야 할 일을 SQL 쿼리로 기록해 둔다.
- 넘겨받아야할 재산을 계약서에 명시하는 컨셉
- 아직 내 소유인것이 아니다 -> 실제 행이 추가되지 않음.
- 계약서에 쓰인대로 이행하면 내 재산이 된다.
- 넘겨받아야할 재산을 계약서에 명시하는 컨셉
위의 3단계를 로컬 트랜잭션으로 묶어서 실행한다.
시스템 코드 / 실행
- GET_LOCK(“dt_lock” + dt_id)
- 각각의 디비에 로직 코드를 호출해서 FLT를 실행한다
- 하나라도 실패하면, 모든 디비에 롤백을 실행한다.
- FLT가 모두 성공하면, 모든 디비에 SLT를 실행한다.
- RELEASE_LOCK(“dt_lock”+ dt_id)
매 단계마다 현재 dt_id, 진행상태, 참여 디비를 기록한다 -> dt_catalog 테이블에
시스템 코드 / 복구
- 끝나지 않은 분산 트랜잭션이 있는지 dt_catalog를 계속 감시한다 (진행하던 서버가 오류로 죽어버린 상항을 위해)
- 있으면 GET_LOCK을 시도
- 성공하면 이어서 마루리 ( 롤백 또는 SLT를 모두 실행)
- 실패하면 그냥 넘어간다.
- 요약
- 로컬 트랜잭션을 사용하여 애플리케이션 레벨 분산 트랜잭션 구현
- FLT / 재산을 압류해서 SQL 텍스트로 바꿈
- FLT가 하나라도 실패되면 롤백한다
- 모든 참여 디비에 FLT가 성공하고 나면 SLT를 실행하여 재산을 재부여 한다.
2단계 커밋 프로토콜 (2-Phase Commit Protocol)
이번 핵데이에서 구현하고 싶던 핵심은 TCC를 이용한 REST 기반 분산 트랜잭션이었다.
TCC가 2PC를 REST로 옮긴 것 같아 2PC 먼저 정리 한다.
2단계 커밋 이란?
-
트랜잭션 처리와, 데이터베이스 컴퓨터 네트워킹에서 정보가 성공적으로 수정되었음을 확인하기 위해서 사용하는 ACP(원자적 커밋 프로토콜)이다. 트랜잭션 성공과 실패(롤백)을 확인하고, 이러한 작업들이 원자적으로 이루어질 수 있도록 조정하는 분산 알고리즘을 제공한다.
- 요약하자면, 2단계 커밋은 커밋과 취소(롤백)를 수행하는데 두 단계를 거친다는 것이다.
- 첫번째 단계는 준비 단계로서, 데이터베이스는 커밋을 위한 모든 단계를 준비한다. 준비단계가 모두 끝나야 두번째 단계로 넘어 간다.
- 두번째 단계는 커밋이 수행된다, 만약 분산 트랜잭션에 참여한 데이터베이스가 준비에 실패한다면 두번째 단계는 커밋이 아닌 취소(롤백)를 수행한다.
분산 트랜잭션이란 네트워크에 분산되어 있는 자원들에 대한 트랜잭션을 의미한다.
예를 들어 MySQL, 몽고디비 같이 따로 구성되어있는 네트워크에 대한 트랜잭션을 처리할때를 말한다.
반대되는 개념으로는 로컬 트랜잭션이 있으며 단일 자원(DB)에 대한 1단계 커밋과 롤백으로 트랜잭션을 수행한다.
트랜잭션은 하나의 RM 만을 포함하고 있다. 이 경우 RM은 보통 트랜잭션을 커밋하고 롤백하기 위한 대부분의 작업을 수행한다. (거의 모든 트랜잭션성 RM이 자체적인 트랜잭션 관리자를 내장하고 있는데, 이는 지역 트랜잭션, 즉 그 RM만이 참여한 트랜잭션을 처리할 수 있다.)
그러나 트랜잭션이 두 개, 혹은 그 이상의 RM (아마도 두 개의 개별적인 데이터베이스, 혹은 데이터베이스와 JMS 큐, 또는 두 개의 개별적인 JMS provider)을 포함하고 있다면 “모두 처리하든지 아니면 아무것도 처리하지 않는”다는 의미론이 그 RM 내에서 뿐 아니라 트랜잭션 내의 모든 RM에게 적용되도록 하고 싶을 것이다. 이런 경우 TPM은 2단계 커밋 을 전개할 것이다.
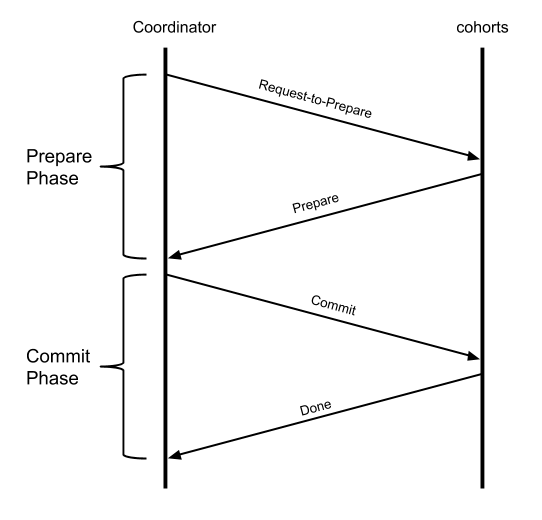
Coordinator(트랜잭션 관리자, TM), Cohorts(자원 관리자, RM)
2단계 커밋 흐름 예시
- TM은 ‘트랜잭션 시작’ 이라는 내용을 로그파일에 작성하고, RM에게 트랜잭션에 대한 요청을 보낸다.
- RM들은 참여하고 있는 디비는 자신의 로그에 트랜잭션을 기재하고 다른 사용자가 접근 못하게 락을 설정하고 작업을 수행한 뒤 커밋할 준비가 되었다고 TM에게 응답한다.
- TM은 커밋할 준비가 되었다는 메세지를 받고 ‘트랜잭선 종료’를 로그에 기록한 뒤, RM들에게 커밋 하라고 통보한다.
- RM들은 이 사실을 트랜잭션 로그에 기록한뒤 커밋을 하고 락을 푼다.
- 만약 커밋하기전에 참여 RM중 문제가 발생하면 TM은 롤백하라고 RM들에게 통보한다.
더 간단한 예시
- 결혼식에서 신랑, 신부에게 ‘결혼에 동의하십니까?’ 를 묻는다.
- 신랑, 신부 모두가 ‘예’ 라고 대답한다면 결혼이 성립된다 (커밋)
- 모두가 ‘아니오’라고 대답하거나 둘중 한명이 ‘아니오’라고 대답한다면 (롤백)
- 누가 먼저 ‘예’ 라고 대답했는지는 중요하지 않다, 왜냐하면 한 사람은 결혼하고 다른 쪽은 결혼하지 않은 상태로 남을일은 없어야 하기 때문.
RM: Resource Manager(자원 관리자) 여기서는 간단하게 데이터베이스라고 생각하자
AP: Application Program
TM: Transaction Manager(트랜잭션 관리자)
TCC (Try-Confirm/Cancel)
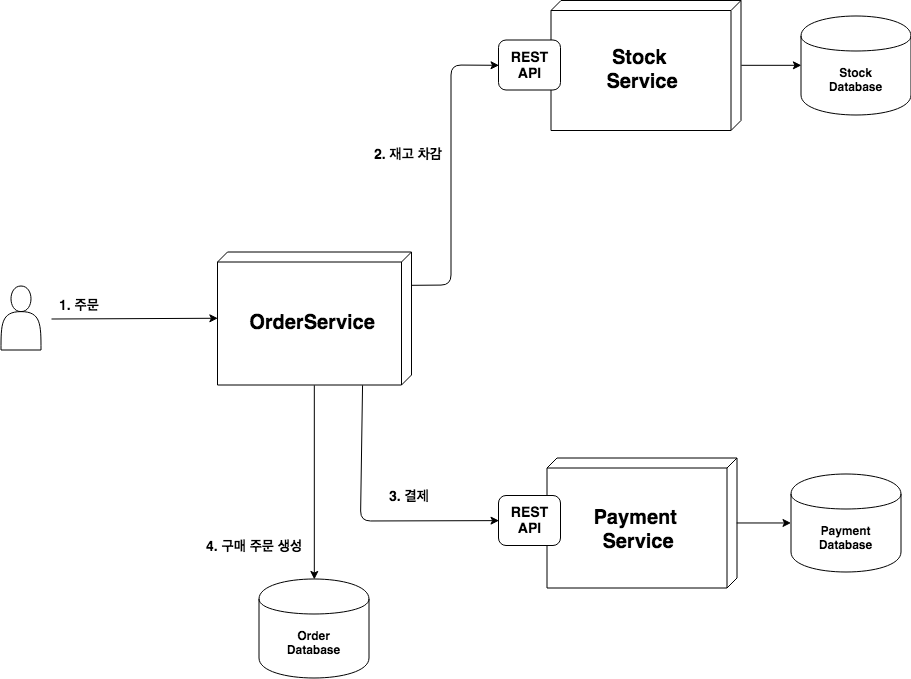
주문을 처리하는 과정에서 재고를 차감하고 결제 처리는 성공했지만, 구매 주문 생성에 실패를 했다면 롤백처리를 해야 일관성 문제가 생기지 않는다.
모노리틱 아키텍처에서는 일반적으로 데이터베이스의 트랜잭션에 의존하게 된다.
하지만 마이크로 서비스의 경우 각 서비스마다 다른 데이터베이스를 사용하는 것이 일반적이고 이를 하나의 데이터 베이스 트랜잭션으로 처리하는 것은 기술적으로 어렵고(이 기종 데이터베이스일 수도 있고) 처리한다 해도 긴 트랜잭션(long transaction)이 발생하기 때문에 효용도 적다.
TCC는 DZone에 올라온 Transactions for the REST of Us 글에서 나온 것으로 분산된 REST 시스템들 간의 트랜잭션을 HTTP와 REST 원칙으로 접근하여 해결하는 방법이다.
관계형 디비의 경우 START TRANSACTION 키워드로 트랜잭션을 시작하고 정상적으로 작업이 끝나는 경우 COMMIT 키워드를 그렇지 않은 경우 ROLLBACK 키워드를 사용한다.
TCC에서 트랜잭션을 제어하는 방법은 관계형 데이터베이스에서 트랜잭션을 제어하는 방법과 유사하다.
주문 처리를 TCC 방식으로 변경하게 되면 아래처럼 된다.
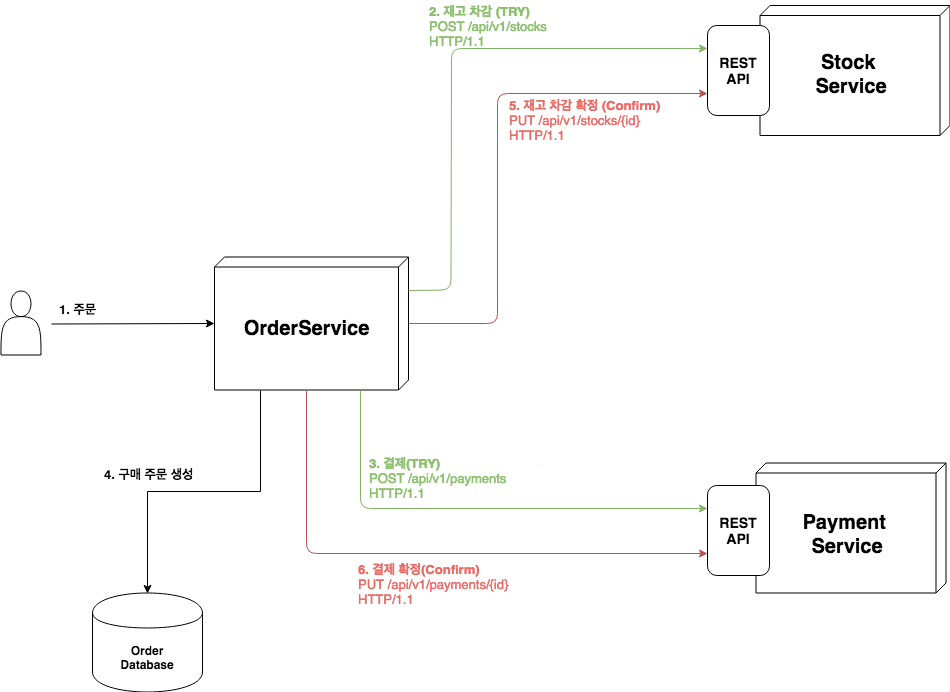
REST API 호출(2단계, 3단계)은 한 번에 끝내는 것이 아니라 2번(Try, Confirm)에 걸쳐 하게 된다.
트랜잭션의 all-or-nothing을 TCC는 REST API를 호출을 시도(Try)하고 전부 확정(Confirm)하거나 전부 취소(Cancel) 하는 것으로 구현한다.
공부를 하며 느낀점
분산 트랜잭션, 로컬 트랜잭션, 글로벌 트랜잭션, 1PC, 2PC, XA
다 처음 듣고 배우는거라 아직도 개념이 잘 정리되지 않는다.
반복해서 정리해야겠다.
참고
http://mommoo.tistory.com/62 [개발자로 홀로 서기]
https://d2.naver.com/helloworld/407507 [DBMS는 어떻게 트랜잭션을 관리할까?]
https://www.slideshare.net/devcatpublications/ndc2015-74962390 [이승재, 마비노기 듀얼: 분산 데이터베이스 트랜잭션 설계와 구현, NDC2015]
http://blog.daum.net/ipajama/37 [2단계 커밋]
http://swdev.tistory.com/4 [소프트웨어 개발 이야기]
https://dzone.com/articles/transactions-for-the-rest-of-us
https://www.popit.kr/rest-기반의-간단한-분산-트랜잭션-구현-1편/