
SQL 레벨업 - 1장 DBMS 아키텍처 (2/2)
3강 DBMS와 실행 계획
권한 이양의 죄악
자바, C, 루비와 같은 절차가 기초되는 언어는 사용자가 데이터에 접근하기 위한 절차(HOW)를 책임지고 기술하는 것이 전제다. 반면에 비절차적인 RDB는 모든 일을 시스템에게 맡겼다. 따라서 숑자가 하는 일은 대상(WHAT)을 기술하는것으로 축소되었다.
그 이유는 ‘비지니스 전체의 생산성 향상’때문이다.
데이터에 접근 하는 방법은 어떻게 결정할까?
RDB에서 데이터 접근 절차를 결정하는 모듈은 쿼리 평가 엔진이라고 부른다. 쿼리 평가 엔진은 입력받은 SQL 구문을 처음 읽어들이는 모듈이기도 하다. 쿼리 평가 모듈은 추가로 파서 또는 옵티마이저와 같은 여러 개의 서브 모듈로 구성된다.
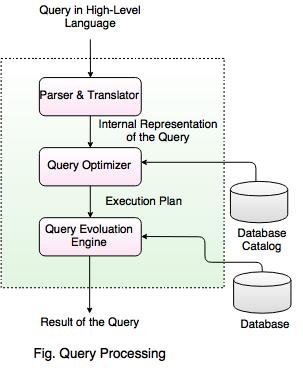
- 파서
파서의 역할은 입력받은 SQL 구문이 항상 구문적으로 올바른지 검사를 하는 역할이다. 그리고 SQL 구문을 정형적인 형식으로 변환한다. 그래야 DBMS 내부에서 일어나는 후속 처리가 효율화된다.
- 옵티마이저
파서를 통과한 쿼리는 옵티마이저로 전송된다. 이때 최적화(옵티마이저)의 대상은 데이터접근법(실행계획)이다. 옵티마이저가 DBMS 두뇌의 핵심.
옵티마이저는 인덱스 유무, 데이터 분산 또는 편향 정도와 같은 조건을 고려한다. 선택 가능한 많은 실행 계획을 작성하고, 비용을 연산하고, 가장 낮은 비용을 가진 실행 계획을 선택한다.
- 카탈로그 매니저
옵티마이저가 실행 계획을 세울 때 옵티마이저에 중요한 정보를 제공하는 것이 카탈로그 매니저.
카탈로그란 DBMS 내부 정보를 모아놓은 테이블로, 테이블 또는 인덱스의 통계 정보가 저장되어 있다. 따라서 카탈로그 정보를 간단하게 ‘통계 정보’라고 칭하기도 한다.
- 플랜평가
옵티마이저가 SQL 구문에서 여러 개의 실행 계획을 세운 뒤 최적의 실행 결과를 선택하는 것이 플랜 평가다. 실행 계획이라는 것은 DBMS가 바로 실행할 수 있는 코드가 아니다. 오히려 사람이 읽기 쉽게 만들어진 문자 그대로의 ‘계획서’다. 읽고 성능이 좋지 않다면 수정을 고려할 수 있다.
이렇게 하나의 실행 계획을 선택하면, 이후 DBMS는 실행 계획을 절차적인 코드로 변환하고 데이터 접근을 수행한다.
옵티마이저와 통계 정보
옵티마이저는 명령대로 잘처리해주는 만능이 아니다. 특히 카탈로그 매니저가 관리하는 통계 정보에 대해서는 데이터베이스 엔지니어가 항상 신경 써줘야 한다.
플랜 선택을 옵티마이저에게 맡기는 경우, 최적의 플랜이 선택되지 않는 경우가 많다. 그 패턴 중 대표 원인으로는 통계 정보가 부족한 경우이다.
- 카탈로그에 포함되어 있는 통계 정보들
- 각 테이블의 레코드 수
- 각 테이블의 필드 수와 필드의 크기
- 필드의 카디널리티(값의 개수)
- 필드값의 히스토그램(어떤 값이 얼마나 분포되어 있는가)
- 필드 내부에 있는 NULL 수
- 인덱스 정보
위의 정보들을 활용해 옵티마이저는 실행 계획을 만든다. 위의 카탈로그 정보가 테이블 또는 인덱스의 실제와 일치 하지 않을 경우 문제가 생긴다.
즉, 테이블에 데이터 삽입/갱신/제거가 수행 될 때 카탈로그 정보가 갱신되지 않는다면 옵티마이저는 오래된 정보를 바탕으로 실행 계획을 세우게 된다. 그 결과 잘못된 계획을 세울 수 밖에 없게 된다.
최적의 실행 계획이 작성되게 하려면
올바른 통계 정보가 모이는 것은 SQL 성능에 굉장히 중요한 요소이다. 따라서 테이블의 데이터가 바뀌면 카탈로그의 통계 정보도 함께 갱신해야만 한다. 수동으로 갱신해야하는 DBMS와 자등으로 갱신되는 DBMS가 존재 한다.
통계 정보 갱신은 대상 테이블 또는 인덱스의 크기와 수에 따라 몇십분에서 몇시간이 소요 되는 실행 비용이 큰 작업이다. 하지만 최적의 플랜을 선택하려면 꼭 필요하므로 갱신 시점을 확실하게 검토해야 한다.
4강 실행 계획이 SQL 구문의 성능을 결정
실행 계획이 만들어지면 DBMS는 그것을 바탕으로 데이터 접근을 수행한다. 통계 정보가 부족하거나, 이미 최적의 방법이 설정되어 있는데도 느린 경우가 있다. 또한 통계 정보가 최신이라도 SQL 구문이 너무 복잡하면 옵티마이저가 최적의 접근 방법을 선택하지 못할 수 있다.
- 실행 계획 확인 방법 -
SQL구문의 지연이 발생 했을때 제일 먼저 실행 계획을 살펴봐야 한다.
# MySQL의 경우
EXPLAIN EXTENDED SQL 구문
# Oracle의 경우
set autotrace traceonly
기본적으로 3개의 기본적인 SQL 구문의 실행 계획이 있다.
- 테이블 풀 스캔의 실행 계획
- 인덱스 스캔의 실행 계획
- 간단한 테이블 결합의 실행 계획
샘플 테이블로 기본 키는 점포ID, 그리고 평가와 주소 지역 데이터를 가지고 있다. 테이블에는 60개의 레코드를 넣고 통계 정보까지 구현해놨다고 가정.
SELECT * FROM shops;
# postgreSQL 의 경우
Seq Scan on shops (const=0.00..1.60 rows=60 width=22)
DBMS마다 출력 포맷이 같지는 않지만 공통적으로 나타나는 부분이 있다.
- 조작 대상 객체
- 객체에 대한 조작의 종류
- 조작 대상이 되는 레코드 수
이 3가지 내용은 거의 모든 DBMS의 실행계획에 포함되어 있다.
- 조작 대상 객체
postgreSQL의 경우 on 이라는 글자뒤에 shops 테이블이 출력된다. 이 부분은 테이블 이외에도 인덱스, 파티션, 시퀀스처럼 SQL 구문으로 조작 가능한 객체라면 무엇이든 올 수 있다.
- 객체에 대한 조작의 종류
실행 계획에서 가장 중요한 부분이다. postgreSQL은 문장의 앞부분에 나온다. ‘Seq Scan’은 순차적인 접근(Sequential Scan)의 줄임말로 해당 테이블의 데이터를 전체를 읽어낸다는 뜻이다.
- 조작 대상이 되는 레코드 수
Rows라는 항목에 출력 된다. 결합 또는 집약이 포함되면 1개의 SQL 구문을 실행해도 여러 개의 조작이 수행된다. 그러면 각 조작에서 얼마만큼의 레코드가 처리되는지가 SQL 구문 전체의 실행 비용을 파악하는데 중요한 지표가 된다.
이 값은 옵티마이저가 실행 계획을 만들 때 나왔던, 카탈로그 매니저로부터 얻은 값이다. 따라서 통계 정보에서 파악한 숫자이므로, 실제 SQL 구문을 실행한 시점의 테이블 레코드 수와 차이가 있을 수 있다.
- 인덱스 스캔의 실행 계획 -
이전에 실행했던 SQL 구문에 조건을 추가한다.
SELECT * FROM shows WHERE shop_id = '00050';
# 결과
Index Scan using pk_shops on shops (cost=0.00..8.27 rows=1 width=320)
Filter (shop_id = '00050'::bpchar)
- 조작 대상이 되는 레코드 수
Rows가 1로 변경 되었다. WHERE 구에서 기본 키가 ‘00050’인 점포를 지정했으므로, 접근 대상은 반드시 레코드 하나이기 때문
- 접근 대상 객체와 조작
이전의 ‘Seq Scan’에서 ‘Index Scan’으로 변경 되었다. 이는 인덱스를 사용해 스캔을 수행한다는 뜻이다.
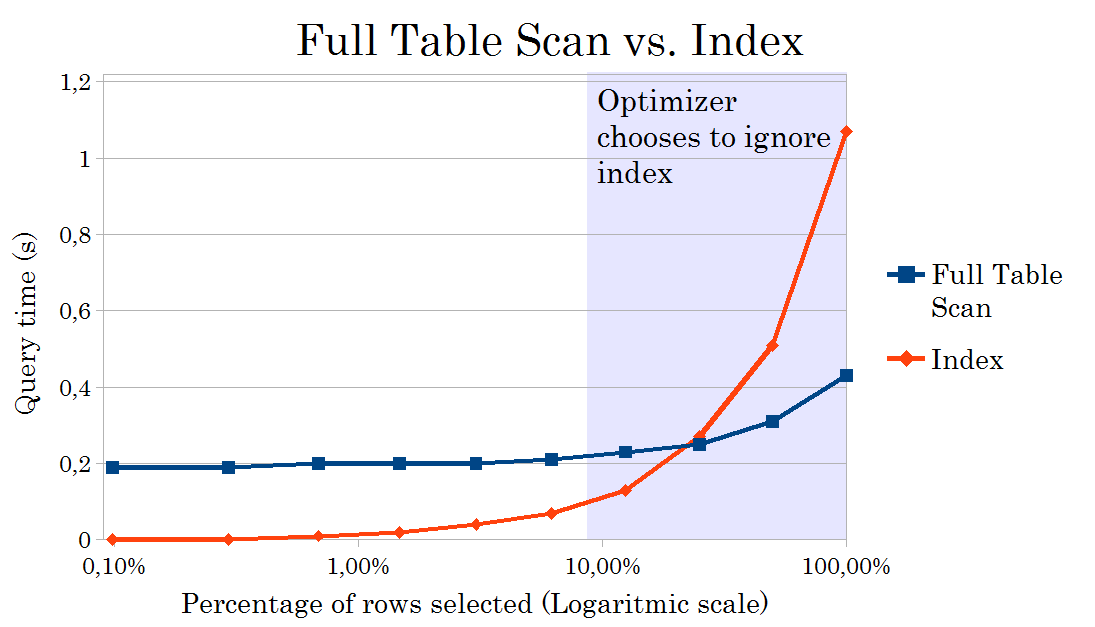
일반적으로 스캔하는 모집합 레코드 수에서 선택되는 레코드 수가 적다면 테이블 풀 스캔보다 빠르게 접근을 수행한다. 이는 풀 스캔이 모집합의 데이터양에 비례하여 처리 비용이 늘어나는것에 반해, 인덱스를 사용할 때 활용되는 B-Tree가 모집합의 데이터양에 따라 대수 함수적으로 처리 비용이 늘어나기 때문이다.
쉽게 말해 인덱스의 처리 비용이 완만하게 증가한다는 뜻으로 특정 데이터 양을 손익 분기점으로 인덱스 스캔이 풀 스캔보다 효율적인 접근을 하게 된다는 뜻이다.
- 간단한 테이블 결합의 실행 계획 -
SQL에서 지연이 일어나는 경우는 대부분 결합과 관련되어 있다. 결합을 사용하면 실행 계획이 상당히 복잡해진다. 옵티마이저도 최적의 실행 계획을 세우기 어렵다. 따라서 결합 시점의 실행 계획 특성이 굉장히 중요한 의미가 있다.
예약에 관한 샘플 데이터를 저장하는 테이블을 추가로 가정한다.
SELECT shop_name FROM Shops s INNER JOIN Reservations R
ON S.shop_id = R.shop_id;
일반적으로 DBMS는 결합할 때 세가지의 알고리즘을 사용한다.
- Nested Loops
- 가장 간단한 결합으로서 한쪽 테이블을 읽으면서 레코드 하나마다 결합 조건에 맞는 레코드를 다른 쪽에서 찾는 방식. 이중 반복으로 구현되므로 중첩 반복이다.
- Sort Merge
- 결합 키(외래 키)로 레코드를 정렬하고, 순차적으로 두 개의 테이블을 결합하는 방법.
- 결합전에 전처리를 해야하는데 작업용 메모리로 워킹메모리를 사용한다.
- Hash
- 이름 그대로 결합 키값을 해시값으로 맵핑하는 방법.
- 해시 테이블을 만들어야 하므로 작업용 메모리 영역을 필요로 한다.
# 결과
Nested Loop (cost=0.14..14.80 rows=10 width=2)
-> Seq Scan on reservations r (cost=0.00..1.10 rows=10 width6)
-> Index SCan using pk_shops on shops s (cost=0.14..1.36 rows=1 width=8)
Index Cond:(shop_id = r.shop_id)
- 객체에 대한 조작의 종류
‘Nested Loop’라고 나오므로 어떤 알고리즘을 사용하는지 알 수 있다. 일반적으로 실행 계획은 트리 구조이다. 이때 중첩단계가 깊을수록 먼저 실행된다. ‘Nested Loop’보다도 ‘Seq Scan’과 ‘Index Scan’의 단계가 깊으므로, 결합 전에 테이블 접근이 먼저 수행된다. 이때 결합의 경우 어떤 테이블에 먼저 접근하는지가 굉장히 중요하다. 같은 주업 단계에서는 위에서 아래로 실행 된다.
예를 들어 Reservation 테이블과 Shop 테이블 접근이 같은 중첩 단계에 있지만, Reservation 테이블에 대한 접근이 위에 있으므로, Reservation 테이블에 대한 접근이 먼저 일어난다.