
Reactive Streams
정의
Reactive Streams is an initiative to provide a standard for asynchronous stream processing with non-blocking back pressure.
논블로킹 배압을 이용한 비동기 데이터 처리의 표준, 그리고 Observer Pattern, Iterator Pattern, Functional Programming의 조합이라고 볼 수 있다.
Iterator
보통 여러개의 요소들이 주어질때 하나씩 순회하며 아이템들을 다루는 대표적인 방법중 하나는 for-loop을 사용하는것이다.
Java에서는 배열과 Collection 인터페이스를 구현한 구현체를 통해서 사용할 수 있다. 즉 Collection은 Iterator를 상속받아 구현한 구현체중 하나이고, 따라서 for (T t : this) 와 같은 문법을 사용할 수 있다.
다시말해 무언가 순회를 해야한다면 Collection을 사용하지 않고도 직접 Iterator를 구현해 사용할 수도 있다.
Observable
옵저버 패턴의 정의는 아래와 같다.
객체 사이에 일 대 다의 의존 관계를 정의해 두어, 어떤 객체의 상태가 변할 때 그 객체에 의존성을 가진 다른 객체들이 그 변화를 통지받고 자동으로 갱신될 수 있게 만든다.
아이템 소스인 Observable은 자신에게 어떤 변화가 생길 때마다 setChanged() 호출하여 Observer들이 변화가 생겼다는 사실을 hasChanged()를 통해서 알 수 있게하고 이후에 notifyObservers()를 통하여 자신에게 등록한 Observer들에게 해당 아이템을 준다.
Iterator와 Observable 비교
Observable은 Iterator 패턴과 달리 소스로부터 아이템을 pulling하는 것이 아닌 아이템 소스로부터 해당 아이템을 핸들링하는 Observer에게 아이템을 push하는 방식이기 때문에 아이템 소스가 될 클래스를 정의한다.
Observer는 아이템 소스로부터 아이템이 오기를 기다려야하므로 두 개의 객체가 동시에 메인 스레드에 생성될 수 없다. 그래서 아이템 소스를 별도의 스레드에서 동작시킨다. Iterable 파트에서는 아이템을 가져와서 핸들링하면되기 때문에 아이템의 소스를 메인 스레드에 정의만 하면 될뿐 별도의 스레드를 띄울 필요는 없었다.
Observer 패턴에서는 for 루프가 Observable에서 정의되어있다. 이것도 Iterable과 아이템을 주는 부분과 핸들링하는 부분으로 나누어서 비교해보면 정반대인 것을 알 수 있다.
아이템을 처리하는 입장에서 Iterable과 Observable을 더 쉽게 비교자면, Iterable의 구조는 여러 개의 아이템에 대해서 내가 하나씩 가져오는 메커니즘인 반면에 Observable은 하나씩 나에게 주는 구조라고 볼 수 있다.
Observable의 장점
둘에 대해서 잘 생각해보면 Iterator 패턴에서 Iterable은 핸들링할 아이템들이 런타임 때 정해진다. 그리고 한 번 Iteratable을 사용하고 다음 코드 플로우로 넘어간다.
반면에 Observable은 Iterable에 비해서 훨씬 더 다양하게 아이템의 소스를 구현할 수 있다. 예를들면 Iterator는 단순히 정해진 사이즈의 for 루프를 한번 돌면 끝이다. 하지만 Observable은 어떤 다른 서버로부터 데이터를 Pulling 하는 방식으로 구현되면, 외부 서버의 데이터가 변할 때마다 Observable에 등록된 Observer는 해당 변화를 감지할 수 있다.
또 다른 점은 Iterator 패턴에서 Iterable의 아이템을 수신할 대상이 한 순간에 한 개의 핸들러에서밖에 해당 아이템을 다룰 수 없는 반면에 Observable에서는 미리 여러개의 Observer를 등록해놓고 아이템을 여러 개의 핸들러에 보낼 수 있다는 장점도 있다.
그래서 왜 Reactive Streams가 필요한걸까?
Reactive 시스템이 등장한 배경에 대해서 간단히 정리하면 다음과 같다.
당시에는 큰 서비스라고하면 몇 십개의 서버로 구성되어있고 몇 초(seconds)의 응답시간을 가져도 괜찮았다. 또한 점검, 배포를 위해 몇 시간 동안 다운되어있어도 괜찮았고 데이터의 사이즈라하면 GB 단위의 규모였다.
하지만 시간이 지나면서 어플리케이션들은 모바일 기기에 배포되기도 하고 수천 개의 프로세서를 가진 클라우드 환경에 된다. 그리고 이제 서비스 사용자들은 milliseconds 단위의 응답 시간이 아니면 답답함을 느끼고 하루 종일 서비스를 사용할 수 있기를 기대한다. 또한 이제 서비스가 다루는 데이터의 규모는 PB에 이른다.
이러한 서비스의 규모가 급변하면서 전통적인 소프트웨어 아키텍쳐로는 이러한 요구사항을 충족시키지 못한다고 생각하게 되었다.
그래서 이러한 요구사항을 만족시키기 위해서 reactive 시스템이 등장하게 된다. 그리고 다음과 같은 아키텍쳐 design principle을 가진다.
- Responsive: responsiveness는 서비스의 사용성의 가장 기본이 된다. 그리고 이 특징은 서비스의 사용성뿐만 아니라 문제가 발생했을 때 특정한 시간 안에 문제를 발견하고 해결할 수 있게 만든다. 그 결과 사용자에게 항상 일정한 수준의 서비스 퀄리티를 보장할 수 있게 한다.
- Resilient: reactive 시스템은 내부적으로 에러가 발생하더라도 여전히 최종 사용자가 해당 서비스를 사용하는데 문제가 없어야 한다. 이러한 특징은 시스템을 구성하는 컴포넌트 중 하나가 실패했을 때 다른 컴포넌트로 에러를 전파하지 않음으로써 만족시킬 수 있고 실패한 컴포넌트에 대한 복구는 사전에 여러개의 레플리카를 둠으로써 하나가 실패하더라도 전체 시스템에는 영향이 가지않도록 설계한다.
- Elastic: 전체 시스템은 외부의 다양한 부하에 대해서 유연하게 대처할 수 있어야한다. reactive 시스템은 부하에 따라서 동적으로 서비스에 리소스 할당량을 늘리거나 줄일 수 있다. 그래서 최종 사용자는 항상 일정한 수준의 서비스 수준을 제공받을 수 있다.
- Message Driven: reactive 시스템은 비동기적으로 message-passing 방식을 통해서 컴포넌트 간의 boundary를 유지하고 결합을 느슨하게 만든다. message-passing 방식을 통해 다음의 목적을 달성할 수 있다: delegate failures as messages, back-pressure, non-blocking communication
그리고 비동기 요청을 위해 CompletableStage, ListenableFuture 등 다양한 라이브러리들을 사용할 수 있는데, 문제는 각각 호환이 안된다는 것이다. 상호 변환을 위해서는 유틸성 로직을 따로 작성해야 한다.
Message Driven Reactive System
위 네 가지 특정 중 Message Driven에 대해서 좀 더 살펴보자. Message Driven의 방식을 통해서 delegate failures as messages, back-pressure, non-blocking communication이라는 목적을 달성할 수 있다고 했는데 각각은 어떤 것을 말하는 것일까?
Delegate failures as messages
시스템에서 메세지의 스트림을 처리하다보면 예기치않게 에러가 발생할 수 있다. 이 때 메세지를 처리하는 쪽에서 메세지 스트림 처리를 중단하고 에러를 핸들링하러 플로우가 넘어가는 것은 바람직하지 않은 방식이다.
여기서 말하는 에러 핸들링의 바람직한 방식은 에러가 발생했을 때 메세지 스트림을 멈추는 것이 아니라 에러를 또하나의 메세지로 생각하고 이를 에러 핸들링하는 쪽으로 전달하는 것이다. 그렇게 된다면 나머지 메세지는 계속 처리하고 발생한 에러에 대해서는 에러 핸들링을 하는 쪽에서 알아서 처리하도록 위임하는 것이다.
중요한것은 에러 핸들링을 위임하고 Publisher 본인은 스트림의 아이템 전달을 멈추지 않는것이다
Non-blocking communication
message-passing 방식은 Non-blocking 방식으로 이루어진다.
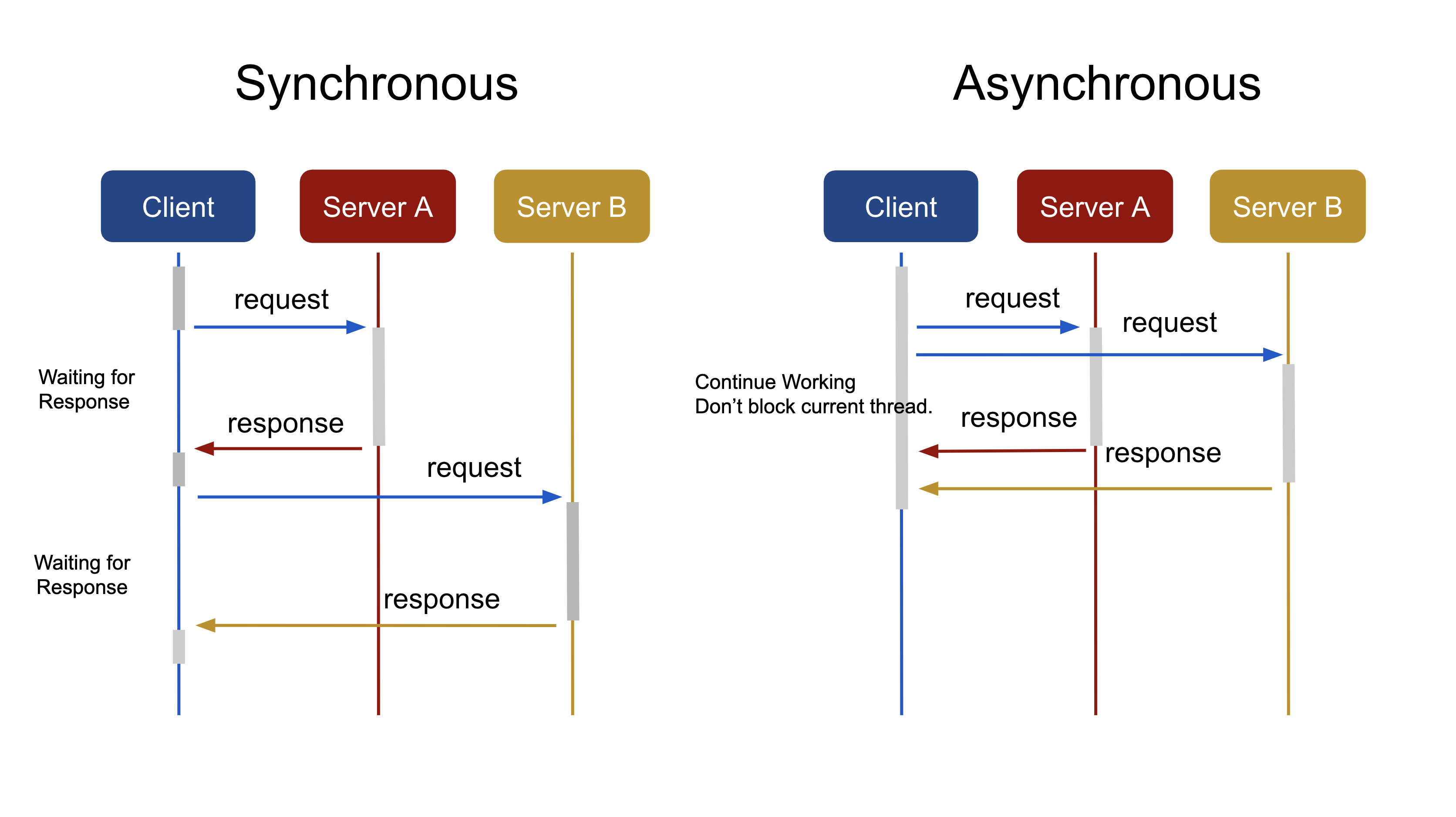
동기 처리 방식과 비동기 처리 방식 비교
동기 방식에선 클라이언트가 서버로 요청을 보내면 응답을 받기 전까지 블로킹 된다.
블로킹된다는것은 현재 스레드가 다른일을 하지 못하고 기다린다는것을 의미한다, 따라서 두 개의 요청을 A, B 각각의 서버에 보낸다면, A의 응답을 받고 나서야 B에게 요청을 보낼 수 있게된다.
반대로, 비동기 방식에서는 스레드가 블로킹되지 않기 때문에 새로운 요청을 할 수 있게 된다.
A에게 요청을 보내고 바로, B에게 또는 C에게 또 다른 요청을 보낼 수 있다.
즉, 비동기 방식을 이용하여 메세지를 전달하면 보낸 입장에서는 상대방으로부터 응답을 듣지 않아도 되고 상대방은 메세지를 보관하다가 처리할 순서가되면 그 때 해당 메세지를 핸들링하면 되기 때문에 전체 오버헤드가 줄어든다는 장점이 있다.
두 방식을 비교했을때 비동기 방식의 장점은 크게 두가지로 볼 수 있다.
- 빠른 속도 - 두 개의 요청을 거의 동시에 보내기 때문에 응답을 기다리는 시간이 줄어든다.
- 적은 리소스 사용 - 스레드가 블로킹되지 않는 시간동안 다른 일을 할 수 있어 효율적이다.
Back-pressure
Back-pressure는 시스템을 구성하는 컴포넌트들 간에 자신의 상황을 주고받을 수 있는 피드백 시스템으로 생각할 수 있다.
스트리밍 처리
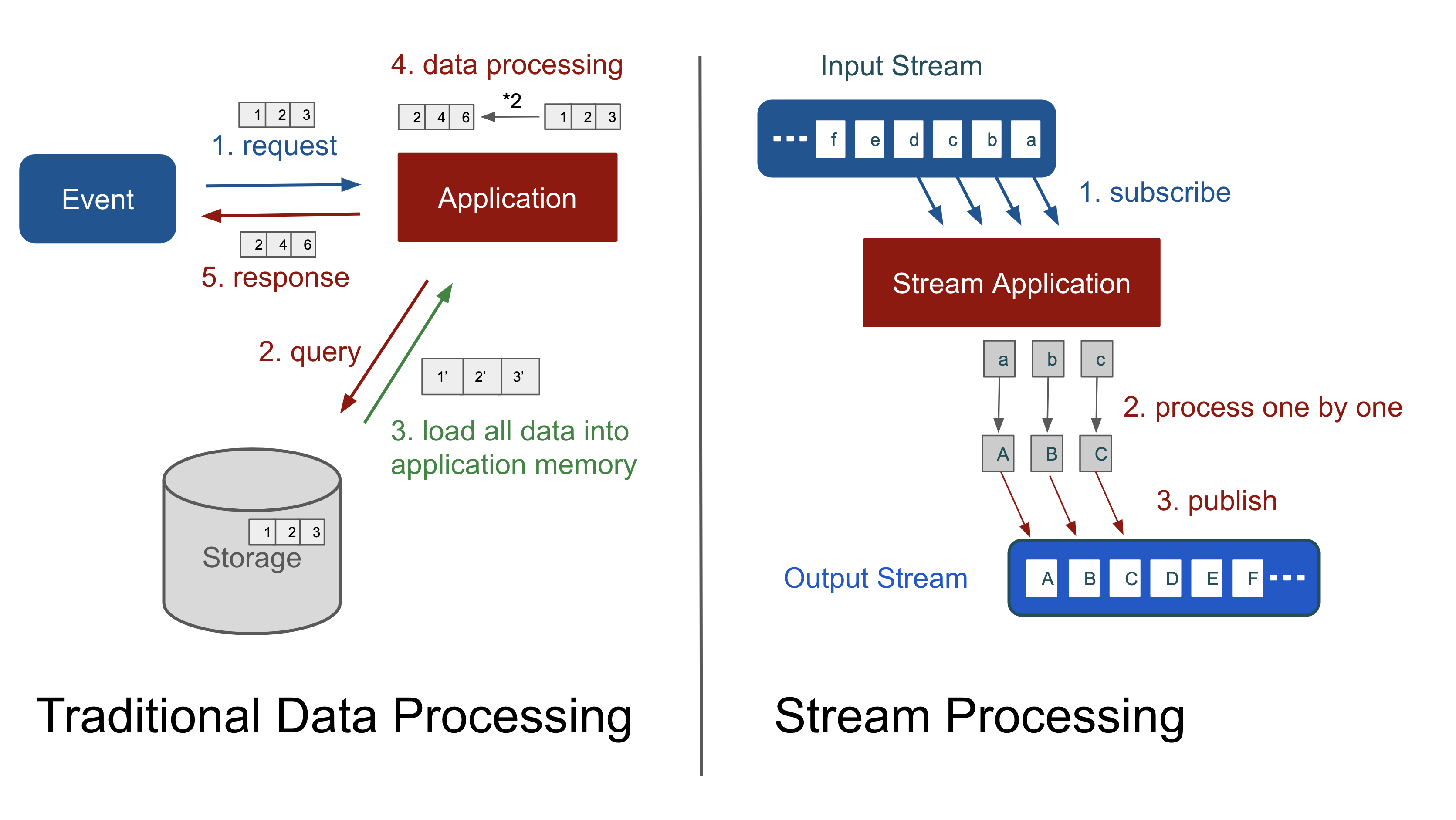
전통적인 데이터 처리 방식과 스트리밍 처리 방식 비교
전통적 처리 방식은 데이터 처리 요청이 오면 payload를 모두 앱의 메모리에 저장한 후에 처리한다. 추가로 필요한 데이터도 저장소에서 조회하여 메모리에 적재하게 된다.
이 방식의 문제점은 전달된 데이터 뿐만 아니라, 저장소에서 가져온 데이터 모두 메모리에 적재되고, 처리를 위해 할당하는 데이터를 메모리에 적재해야 응답을 만들 수 있게 된다.
따라서 메모리에 적재될 데이터의 크기가 크다면 Out Of Memory(OOM)이 발생하게 된다.
반대로 스트리밍 처리 방식은 입력 데이터에 대한 파이프라인을 만들어 데이터가 들어오는 대로 물 흐르듯(flow) 구독과 발행, 처리까지 한번에 연결할 수 있다. 이렇게 되면 많은 양의 데이터도 탄력적으로 처리 가능하기에 적은 메모리로도 많은 양의 데이터를 다룰 수 있게 된다.
Observer Pattern의 한계와 Reactive Streams의 해결법
옵저버 패턴에서는 기본적으로는 발행자(Subject)가 구독자(Observer) 에게 데이터를 밀어넣는 방식으로 데이터가 전달된다.
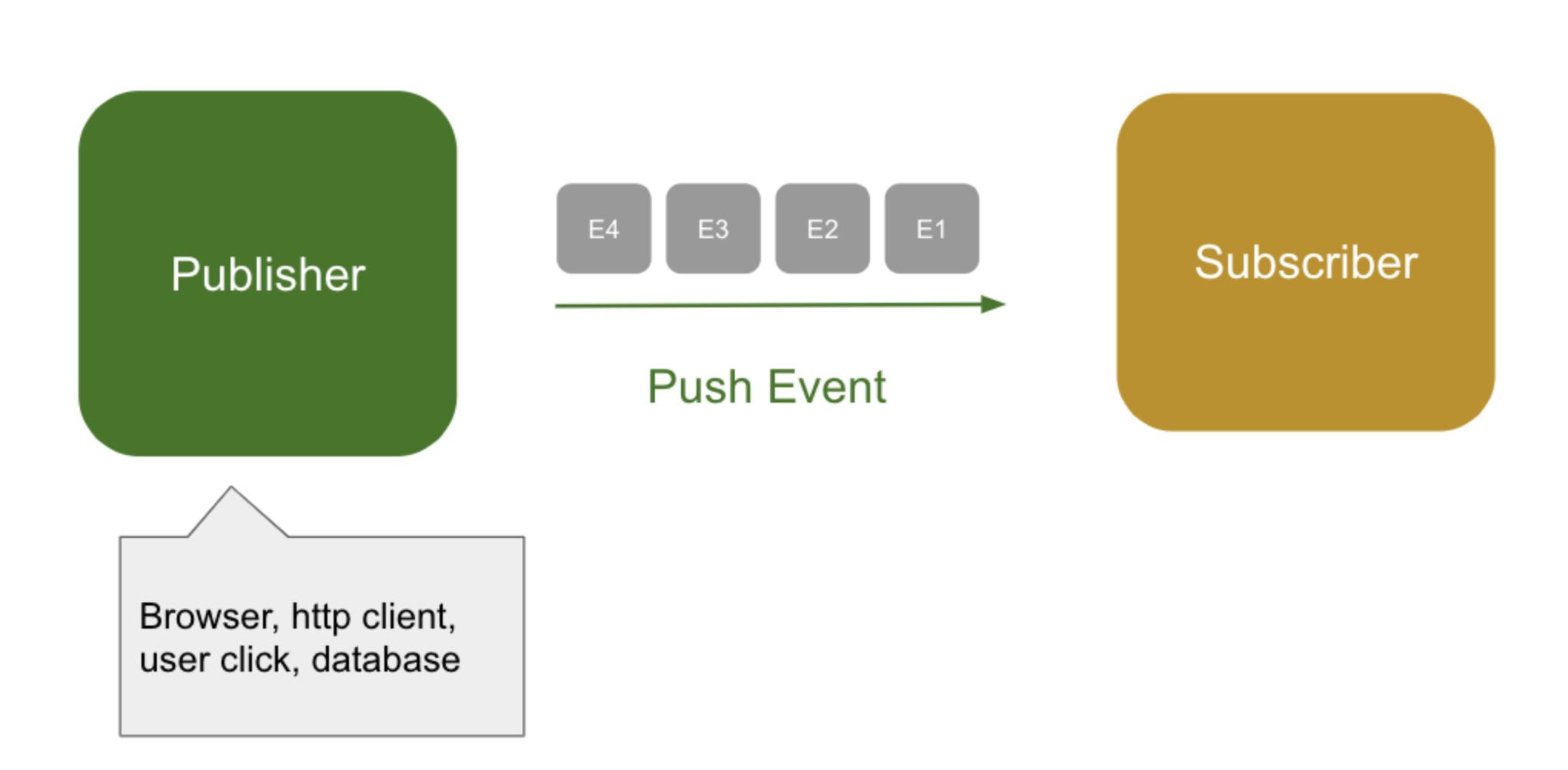
Observer 가 이벤트를 처리하는 속도보다, Subject 가 이벤트를 발행하는 속도가 빠르다면?
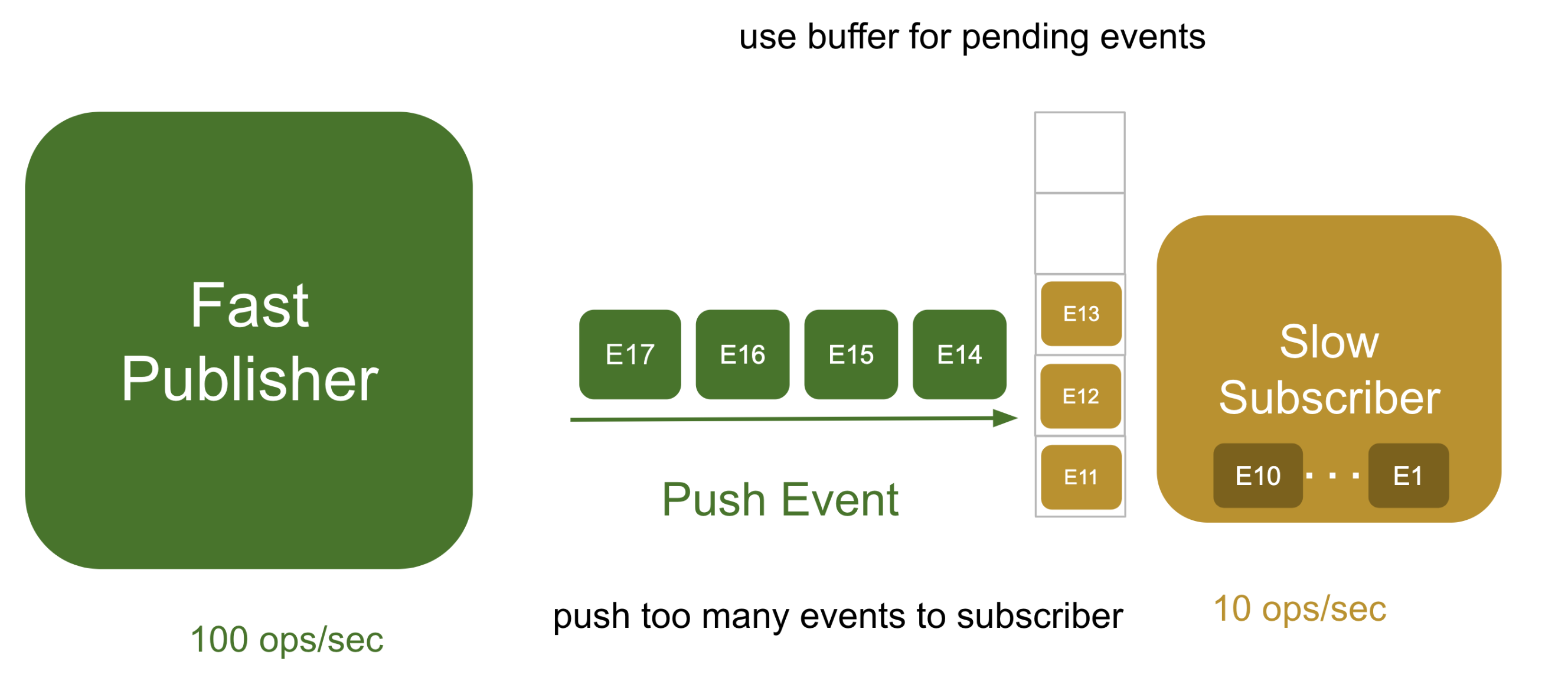
발행자는 구독자의 상태를 고려하지 않고 데이터를 전달하는데만 집중하게 된다. 이때 만약 발행자가 1초동안 100개의 메세지를 보내지만, 구독자는 1초에 10개의 메세지를 처리할 수 없다면 위에서 말한 OOM이 발생하거나 또는 메모리에 적재하지 못해 데이터 유실이 발생할 수 있게 된다.
이러한 일을 방지하기 위해 Queue 또는 Buffer 를 만들어 대기중인 메세지들을 저장해 해결할 수 있다.
하지만 서버가 사용할 수 있는 메모리는 한정되어있기에, 초당 100개의 데이터를 메모리에 계속 푸시한다면 큐는 금방 꽉차게 되고 overflow가 발생하게 된다.
이 경우 큐를 구성하는 방법은 고정 길이의 큐 또는 가변 길이의 큐로 나뉠 수 있게 된다.
고정 길이의 큐를 사용하게 된다면 큐가 꽉차있을때 신규로 수신된 메세지를 거절하고, 거절된 메세지는 재요청하게 되는데 재요청 과정에서 네트워크와 CPU 연산이 추가로 발생하게 된다.
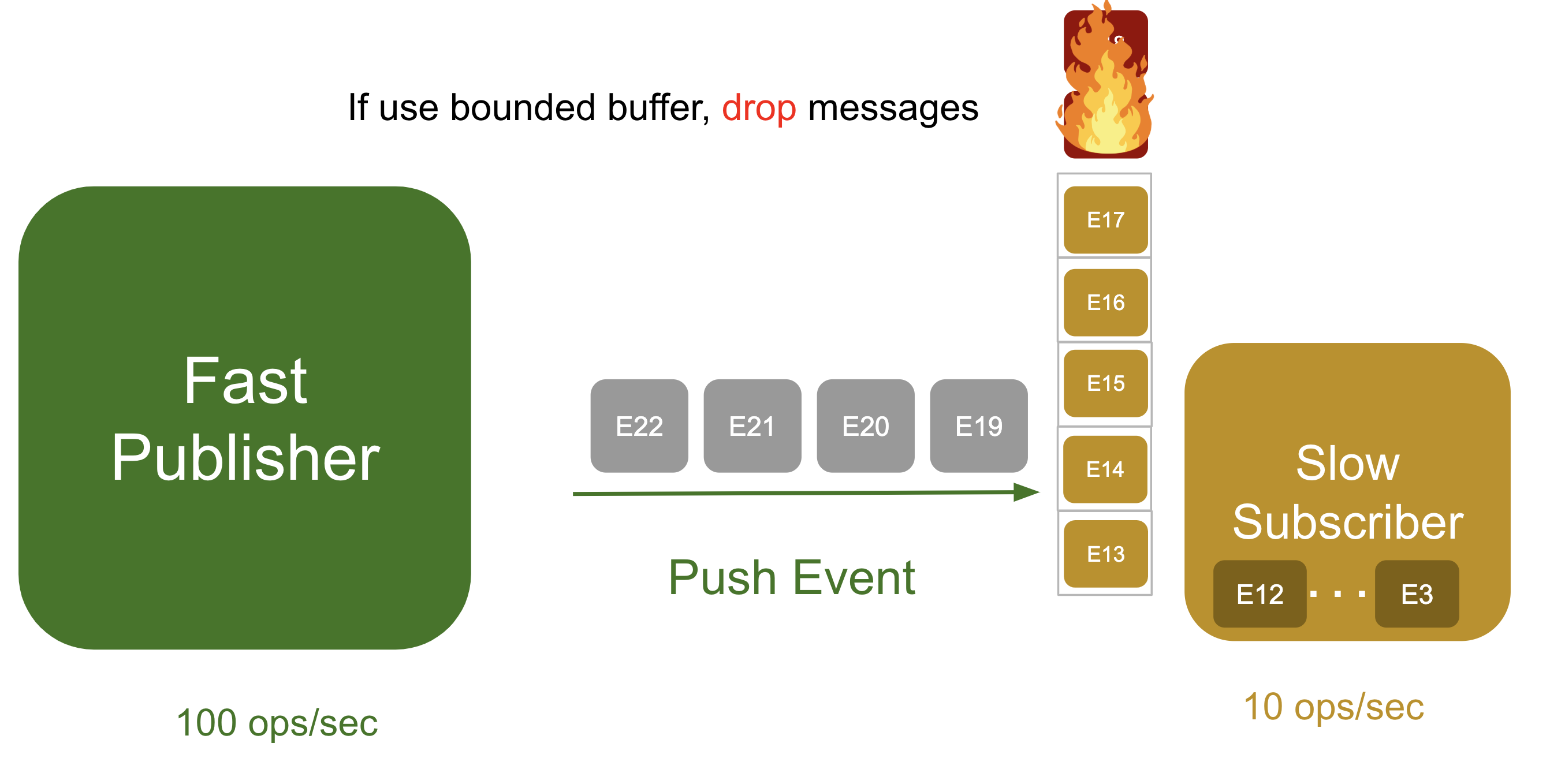
가변 길이의 큐를 사용하게 된다면 OOM 에러가 발생할 수 있게 된다, 누가 가변을 사용할까 생각하지만
자바에서 가장 많이 사용되는 List도 가변 길이 자료 구조이다. 예를들어 DB가 발행자가 되고 서버가 구독자가 되었을때 List에 모두 담으려고 한다면 서버가 정상적인 응답을 할 수 없게 된다.
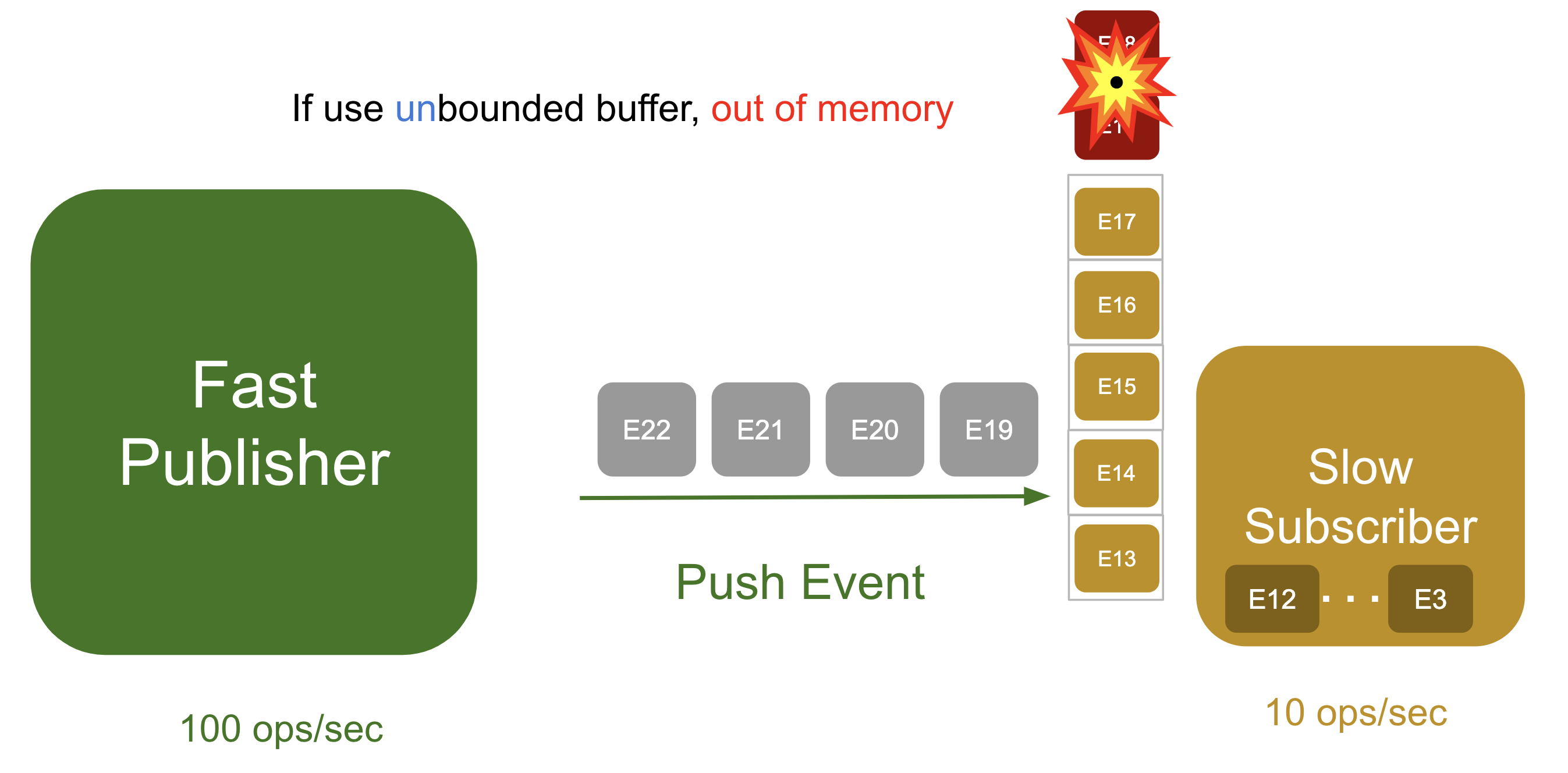
그럼 어떻게 해야할까?
답은 간단하다 구독자가 필요한 데이터 수 또는 받을 수 있는 데이터 수 만큼만 보내달라고 발행자에게 요청하면 되는데, 이 방식이 pull 방식이라 불리우며 back-presure의 기본원리이다.
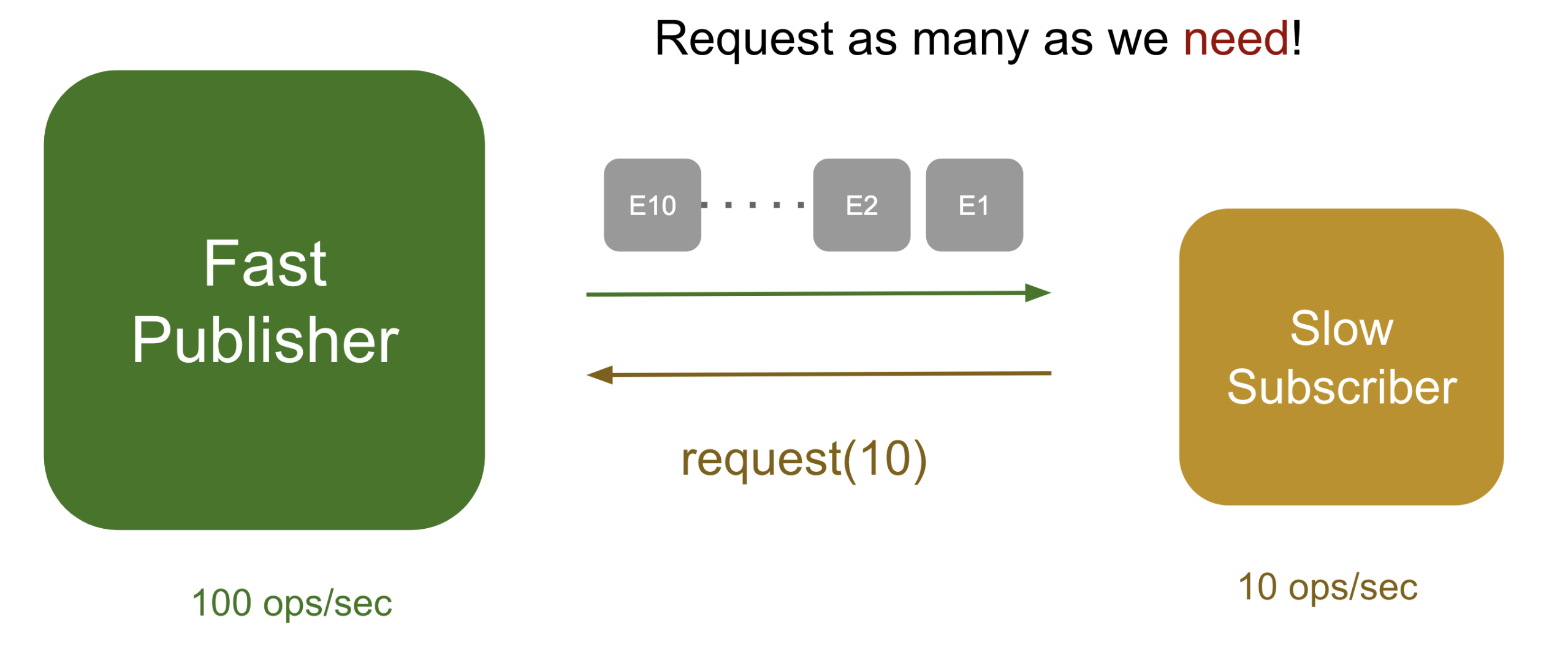
Pull 방식에선 구독자가 데이터를 10개만 처리 가능하다고 발행자에게 요청한다면 발행자는 10개의 데이터만 구독자에게 전달하게 되므로 OOM에서 벗어날 수 있게 된다.
Reactive Streams
이러한 Reactive 시스템을 만들기 위해 Reative Streams를 만들게 되었다.
Reactive Streams API를 기준으로 Netflix의 RxJava, Pivotal의 WebFlux, Lightbend의 Akka가 구현되었다.
Reactive Streams API
어마어마한 구현체들을 보니, 근본이 된다는 Reactive Streams API가 엄청 복잡하고 어려울거라는 생각이 들지만
실제로는 비교적 간단한? 인터페이스로 구성 되어있다. (processor는 나중에)
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}
public interface Subscription {
// n = LONG.MAX -> push
// n = 1 -> pull
public void request(long n);
public void cancel();
}
Reactive Streams 스펙을 다이어그램으로 표현하면 아래와 같다.
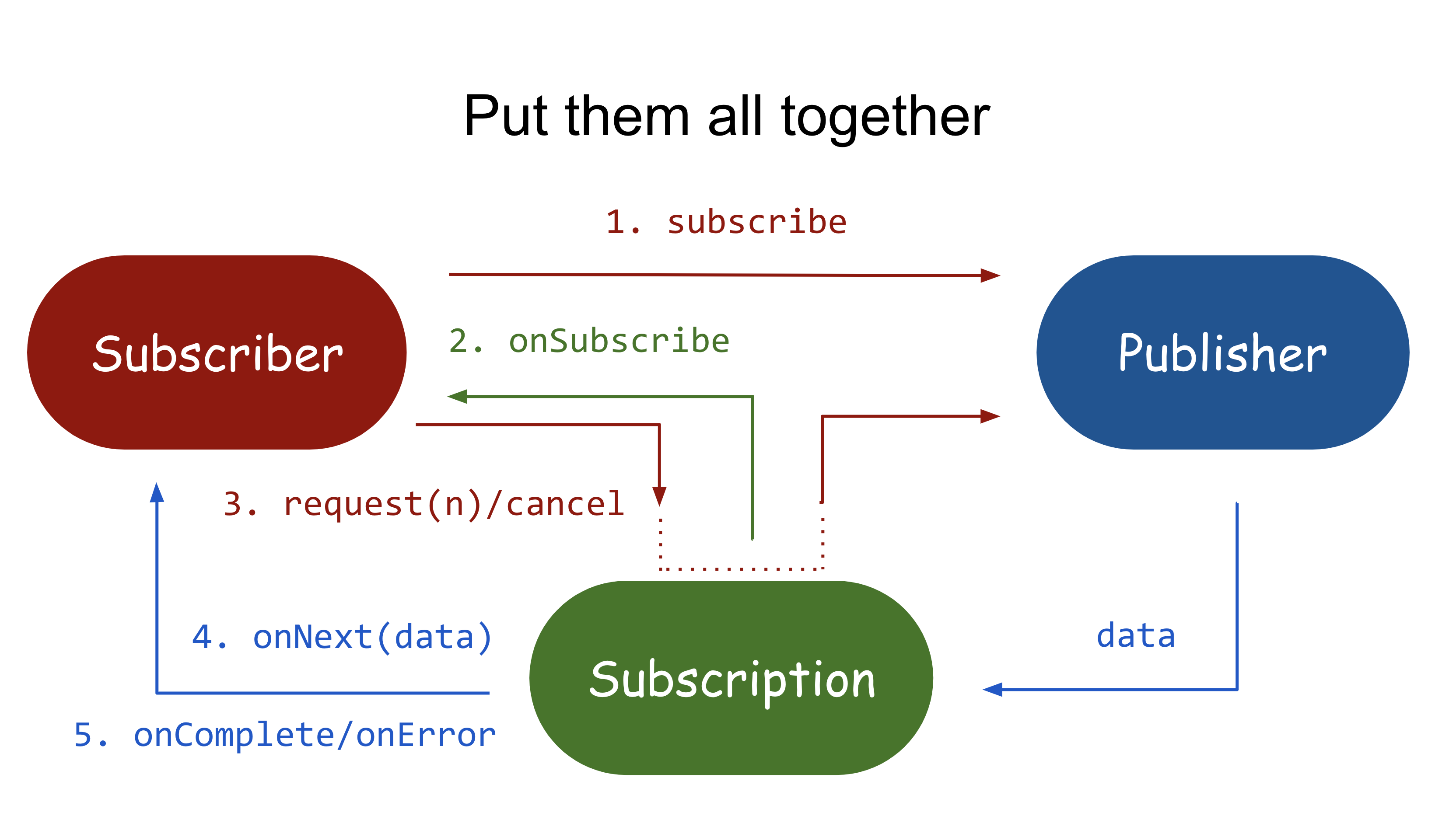
- Subscriber는 Publisher에게 subscribe(Subscriber) 를 통해서 이벤트 구독을 시작한다.
- Publisher는 Subscriber에게 Subscription 객체를 만들거나 관리하고 있는 Subscription 객체를 onSubscribe(Subscription) 메소드를 통해 전달한다. Subscription을 통해서 Subscriber는 Publisher와 직접적으로 통신할 필요가 없어진다.
- Subscription은 Subscriber로부터 전달받는 피드백을 통해서 Publisher로부터 아이템을 가져오고 그것을 - Subscriber에게 전달한다. Publisher와 Subscriber는 둘 사이를 직접적으로 몰라도된다.
- 정상적인 경우라면 Subscriber의 onNext(Object) 메소드를 호출해서 아이템을 전달한다. 그리고 만약 Publisher 자신이 가지고 있는 아이템을 모두 전달했다면 onComplete() 를 호출해서 Subscriber에게 그 사실을 알려준다. 마지막으로 에러가 발생했을 경우 onError(Throwable) 를 통해서 문제가 발생했다는 사실을 알려준다.
public static void main(String[] args) {
Publisher pub = new Publisher() {
@Override
public void subscribe(Subscriber subscriber) { ... }
}
Subscriber<Integer> sub = new Subscriber<>() {
@Override
public void onSubscribe(Subscription subscription) { ... }
@Override
public void onNext(Integer item) { ... }
@Override
public void onError(Throwable throwable) { ... }
@Override
public void onComplete() { ... }
}
pub.subscribe(sub);
}
- 전체적인 구조는 위와 같다. 각각 Publisher, Subscriber의 구현체를 구현하고 pub.subscribe(sub) 을 통해 Subscriber가 Publisher가 주는 아이템을 구독하는 형태이다.
- 이제 각각의 메소드를 살펴보면서 어떻게 위의 다이어그램처럼 동작하는지 비교해보자.
Publisher pub = new Publisher() {
Iterable<Integer> it = Arrays.asList(1, 2, 3, 4, 5);
@Override
public void subscribe(Subscriber subscriber) {
ExecutorService es = Executors.newSingleThreadScheduledExecutor();
Iterator<Integer> iterator = it.iterator();
subscriber.onSubscribe(new Subscription() {
Future<?> f;
@Override
public void request(long n) {
this.f = es.submit(() -> {
long left = n;
try {
while (left > 0) {
if (!iterator.hasNext()) {
subscriber.onComplete();
es.shutdown();
break;
}
subscriber.onNext(iterator.next());
left -= 1;
}
} catch (Exception e) {
subscriber.onError(e);
}
});
}
@Override
public void cancel() {
f.cancel(true);
}
});
}
};
- Subscriber가 subscribe() 를 통해 구독을 시작하면 Publisher는 자신과 Subscriber을 연결해줄 수 있는 중간 객체인 Subscription 객체를 만들어서 Subscriber에게 전달한다.
- 이후에 Subscriber는 Subscription을 통해서 Publisher에게 아이템을 달라고 back-pressure를 할 수 있다.
- Subscription은 Reactive Streams API를 보면 request(long)과 cancel() 을 구현해야한다. 이는 둘다 Subscriber를 위한 인터페이스이며 Subscriber는 자신의 필요에 따라 아이템을 요청할 수도 있고 구독을 취소할 수 있다. 이와 같이 Reactive Streams는 마냥 push 모델이 아니라 필요에 따라 pulling 모델도 같이 적용하고 있다.
- Subscription 내부에서는 요청이 들어오면 Publisher의 아이템을 가져와서 Subscriber의 onNext(), onError() 를 통해 아이템을 넘겨주거나 자신의 상황을 메세지의 형태로 알려준다.
- 마지막으로 Publisher가 자신이 가진 아이템을 모두 넘겨주었을 때 onComplete() 을 통해서 스트림이 끝났음을 알려준다.
Subscriber<Integer> sub = new Subscriber<>() {
final static int MAX_BUFFER_SIZE = 2;
Subscription subscription;
List<Integer> buf = new ArrayList<>();
@Override
public void onSubscribe(Subscription subscription) {
this.subscription = subscription;
this.subscription.request(MAX_BUFFER_SIZE);
}
@Override
public void onNext(Integer item) {
buf.add(item);
if (buf.size() >= MAX_BUFFER_SIZE) {
buf = new ArrayList<>();
this.subscription.request(MAX_BUFFER_SIZE);
}
}
@Override
public void onError(Throwable throwable) {
System.out.println(throwable);
}
@Override
public void onComplete() {
buf = new ArrayList<>();
}
};
- Subscriber는 구독을 시작하고 onSubscribe() 를 통해서 Subscription 객체를 넘겨 받는다. 이후 Subscription의 request() 를 통해서 아이템을 요청한다.
- onNext()를 통해서는 자신이 구독한 아이템이 넘어오게되고 자신의 상황에 맞춰서 다음 번에 받을 아이템의 양을 조절한다.
결론 - 그래서 이걸 다 고려하고 구현해야 할까?
답은 아니다.
학습 목적으로는 직접 구현하는것도 좋은 시도이겠지만, 서비스를 운영하는 입장에서는 전문가들이 만들어 둔 많은 구현체들을 사용하면 된다.
- 순수하게 스트림 연산 처리가 필요하다면 RxJava, Reactor Core, Akka Streams 등을 사용
- 저장소의 데이터를 Reactive Streams로 조회하고 싶다면 Reactive Mongo, R2DBC 등을 사용
- 웹 프로그래밍과 연결된 Reactive Streams가 필요하다면 Spring WebFlux, Armeria, Vert.x 등을 사용
위에서 언급한 구현체들을 사용함으로서 얻을 수 있는 또 하나의 이점은 각각의 구현체를 섞어서 사용이 가능하다는 점이다.
// Initiate MongoDB FindPublisher
FindPublisher<Document> mongoDBUsers = mongodbCollection.find();
// MongoDB FindPublisher -> RxJava Observable
Observable<Integer> rxJavaAllAges =
Observable.fromPublisher(mongoDBUsers)
.map(document -> document.getInteger("age"));
// RxJava Observable -> Reactor Flux
Flux<HttpData> fluxHttpData =
Flux.from(rxJavaAllAges.toFlowable(BackpressureStrategy.DROP))
.map(age -> HttpData.ofAscii(age.toString()));
// Reactor Flux -> Armeria HttpResponse
HttpResponse.of(Flux.concat(httpHeaders, fluxHttpData));
예제 코드와 같이 MongoDB에서 조회한 데이터를 Http 응답하려고할때 각각을 조합하여 사용할 수 있다.
추가
Reactive Streams을 사용해 비동기, 병렬 처리를 하려면?
Reactive Streams API 명세를 보면, Publisher 가 생성하고 Subscriber 가 소비하는 모든 신호는 non-blocking 이어야한다고 정의 되어있다. 따라서, Publisher - Subscriber 를 구현시, block이 되지않도록 해야한다.
위 내용을 스펙에 맞게 구현 했다면, 멀티코어를 모두 활용하기 위해서 Subscriber.onNext() 함수를 병렬로 호출해야하는데, 이 방법은 스펙에 맞지 않으므로 사용할 수 없다.
onNext, onError, onComplite와 같은 함수 호출은 스레드 안전성을 보장하여 신호를 보내야하며, 멀티 스레드에서 수행될 경우, 외부에서 동기화를 해줘야한다. 따라서, 순차적으로만 onNext 를 호출할 수 밖에 없다.
즉, Publisher 가 멀티스레딩하여 Subscriber.onNext() 함수 를 동시에 호출할수 없게된다.
그렇다면, 도대체 어떻게 병렬로 구현할 수 있을까?
다음에 알아보자…

P.S.
글 여러개를 정독하며 쓰다 힘들어서 거의 복붙 했습니다…
참고에 남겨둔 링크들 모두 엄청난 글들이니 모두 백번씩 정독하세요…
참고
- https://sjh836.tistory.com/182
- https://engineering.linecorp.com/ko/blog/reactive-streams-with-armeria-1/
- https://www.getoutsidedoor.com/2020/11/23/reactive-streams-%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C/
- https://www.reactivemanifesto.org/