
about C10K problem
The C10k Problem
영어로는 The C10k Problem, 한글로는 1만 개의 클라이언트 문제에 대해서 알아보자
C10k 문제가 무엇이냐?
이 문제는, 1999년 단 케겔이 처음 제시한 이야기로
1만개의 클라이언트를 동시에 처리할 수 있는 네트워크 I/O 모델을 설계 방법을 묻는 말이다.
여기서 동시 처리 기준이 되는 시간은 명확하지 않지만 보통 1초를 말한다.
20세기에는 컴퓨팅 리소스가 넉넉하지 않았고 꽤나 부담스러운 가격이었다.
지금은 휴대폰보다 안좋은 성능의 스펙인 1GHz 성능의 1코어 CPU, 2GB 메모리의 컴퓨터를 사려면 100만원이 훌쩍 넘었다.
이런 상황에 급격히 늘어나는 웹 사이트를 운영하는 사람이라면 1만 개의 클라이언트 문제는 꼭 해결하고 넘어갸아할 문제였다.
1999년도부터 시간이 20년이 조금 더 지난 지금
현재 컴퓨터가 아닌 휴대폰 조차 갤럭시 s21 스펙은 cpu 2.9GHz 옥타코어, ram 12gb 이라고 한다.
이렇게 하드웨어 스펙이 발전한 상황에서 이 문제는 유효할까?
답은 아직도 유효하다. 그리고 생각보다 많은 곳에서 이 문제를 해결하지 못한다.
더 정확히 말하면, 사람들은 자신이 만든 서버가 1초에 얼마나 많은 요청을 처리할 수 있는지 모른다고 한다
그 원인으로는 라이브러리와 프레임워크의 발전때문이라고 볼 수 있다.
20세기 개발자들은 서버 프로그램을 만들기 위해 소켓 동작을 이해하고, 더 나아가 연결을 맺고 끝는 과정들을 이해하고 있어야 했다.
하지만 21세기 개발자들은 라이브러리와 프레임워크가 이런 복잡하고 어려운 작업들을 블랙박스로 만들어 주었다.
즉, 21세기 개발자들은 프레임워크갖 제공하는 함수, 핸들러 등록만으로 서버 프로그램을 만들 수 있게 되었다. 쉽게 말하자면 복잡하고 귀찮은것들은 라이브러리와 프레임워크에게 위임하고 생산성에만 집중할 수 있게 되었다.
const http = require('http');
const server = http.createServer((request, response) => {
// TODO
});
특히나 javascript처럼 언어 하나만 알아도 backend, frontend에서 동작하는 프로그램을 만들 수 있다
javascript is cooooooooooooool
21세기에 코드에는 더이상 내부적으로 메시지를 어떻게 주고 받는지 정의하는 부분이 없다.
성능이 조금 떨어져도 정의한 스펙에 맞춰 개발하는게 더 중요한 시대가 도래했다.
성능 개선은 서비스 출시 후에 해도 늦지 않다는게 보편적인 생각이 되었다.
이렇다 보니 네트워크에서 병목이 생긴다면 (네트워크에서 병목이 생긴다는 사실을 모르는 경우도 많음)
데이터베이스에 문제가 있나? 또는 캐시를 추가해야하나? 같은 생각만 하게 된다
잘못된 접근은 아니지만 실제로는 연결 풀이 부족하거나 비효율적이어서 나타나는 상황이 대부분이다
다시 본론으로 돌아와서 왜 C10k Problem 은 아직도 유효한걸까?
그리고 이 문제를 해결하기 위한 방법을 통해 10만개 또는 100만개의 클라이언트를 처리할 수 있는데 도움이 되지 않을까?
이제부터 알아보도록 하겠다
- 네트워크 I/O 모델
- 블로킹과 논블로킹
- sync, async
- 싱글 스레드와 멀티스레드
- 운영체제에서 제공하는 I/O 모델
- 리눅스에서 select, poll, epoll
- 윈도우에서 IOCP, RIO
- 언어에서 제공하는 I/O 모델
- Python
- JAVA
- NodeJs
네트워크 I/O 모델
네트워크 I/O모델은 소켓이 동작하는 방식을 정의한다.
소켓이 요청 메세지를 받는 시점부터 응답 메세지를 보내기 까지 모든 행동을 포함하기 때문에
어떤 모델을 사용 하냐에 따라메세지 처리량이 달라진다.
블로킹(block) 모드
블로킹 모드는 하나의 소켓이 모든 메세지를 받거나 보낼때 까지 기다리는 방식이다.
서버는 요청을 한없이 기다린다는 단점이 있지만, 소켓의 다음 동작을 쉽게 예측할 수 있어 개발이 쉽다는 장점이 있다.
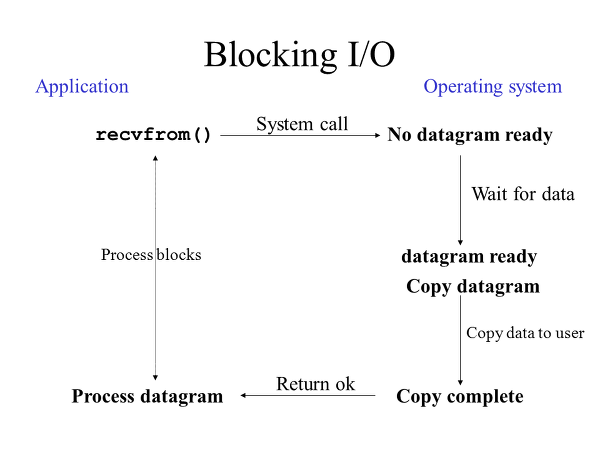
논블로킹(non-blocking) 모드
논블로킹모드는 요청을 받거나 보낼 수 있는 상황에서는 처리하지만, 그러지 않은 경우에는 처리하지 않고 즉시 종료한다.
처리가능한 상황에서만 처리하기 때문에 서버가 기다리는 시간이 없어 효율적이지만, 소켓 상태를 쉽게 예측할 수 없다는 단점이 있다.

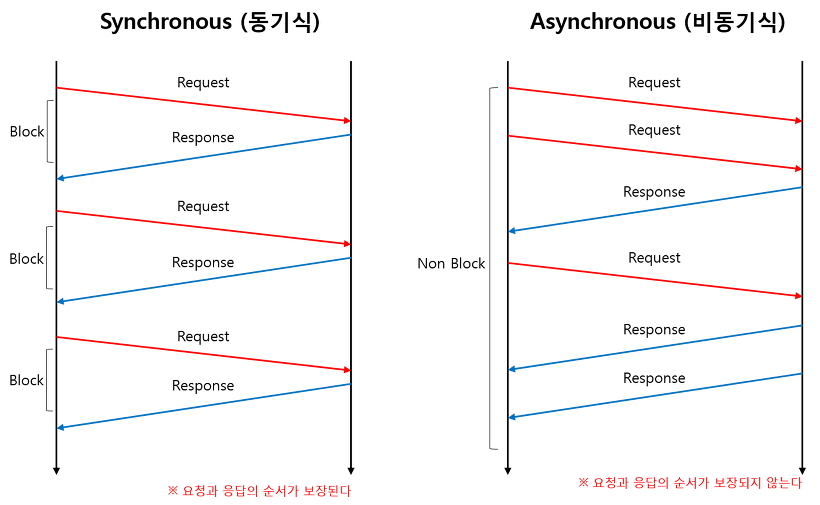
순차적(sync) 방식
순차, 비순차 방식은 네트워크 I/O모델에 속하지는 않지만 메세지를 주고 받기 위한 모델이라는 관점에서는 포함될 수 있다.
순차 방식은 요청 메세지를 받은 후 응답을 보내는 과정이 묶여있다고 생각하면 된다.
먼저 온 클라이언트 요청에 대한 응답을 보낸 후 다음 클라이언트 요청을 처리하기 때문에
클라이언트가 메세지를 보낸 순서에 따라 응답 순서가 결정된다는 특징이 있다.
순차 방식은 블로킹, 논블로킹에 관계없이 순차적으로 메세지를 주고 받는다.
비순차적(async) 방식
비순차 방식은 요청 메세지를 받는 부분과 응답 메세지를 보내는 부분이 분리되어 있다.
순차 방식과 달리 요청 순서와 응답 순서가 보장되지 않지만, 서버가 응답 보낼 준비가 될 때 보낼 수 있다는점에서
효율적으로 클라이언트의 요청을 처리할 수 있다.
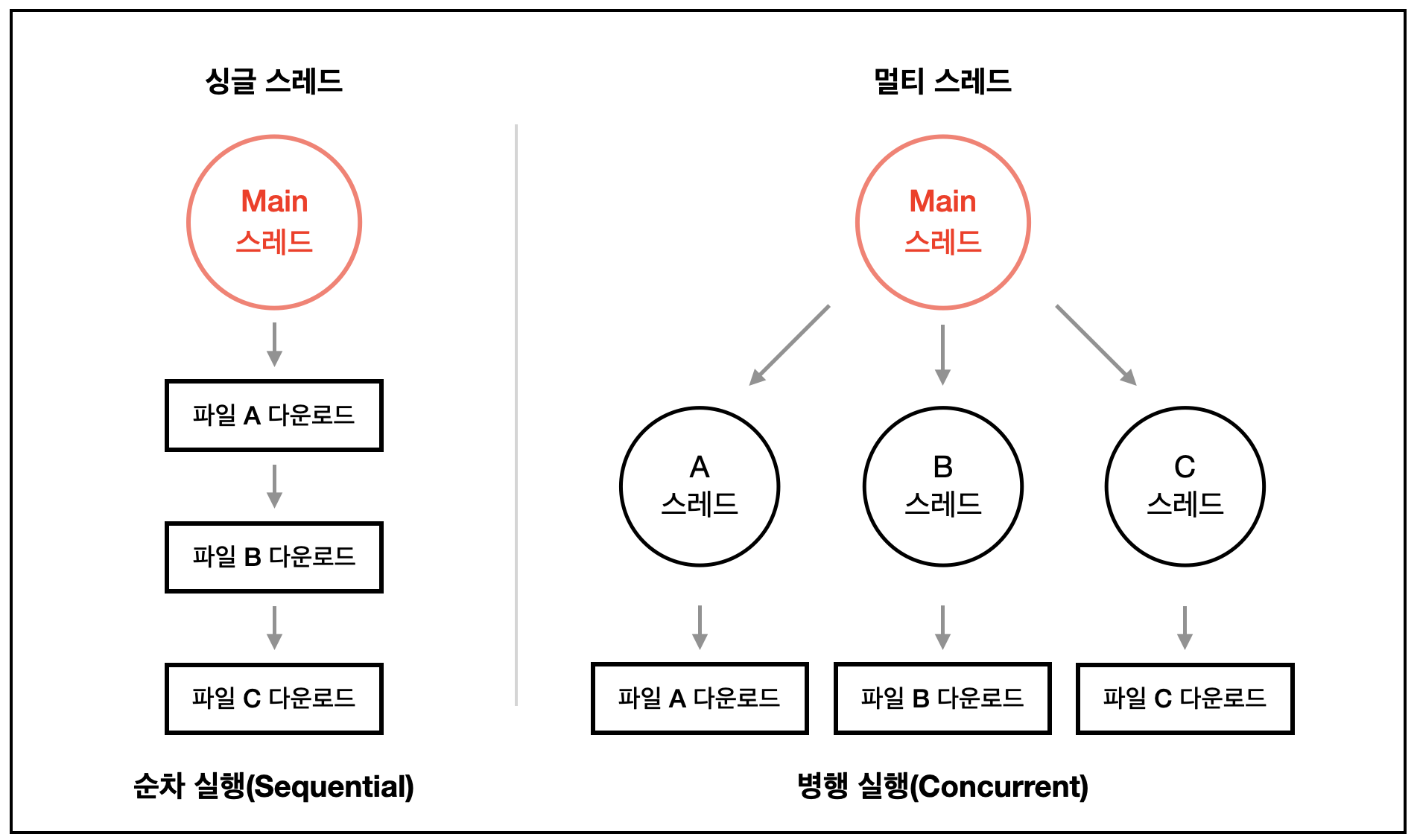
멀티 스레드
스레드 개수는 소켓의 동작 방식과 직접적인 관련이 없지만,
소켓 처리 방식에 따라 여러 스레드에서 소켓을 처리할 수 있고
하나의 스레드에서 모든 소켓을 처리할 수 있다.
클라이언트 하나에 스레드 하나를 할당할 경우 소켓이 어떻게 동작하든 상관 없겠지만
너무 많은 스레드를 사용하면 스레드를 유지하는 메모리가 커지고 OS 스케줄러또한 비효율적으로 동작하게 된다.
싱글 스레드
스레드 하나에서 모든 클라이언트 소켓을 처리해야 하는 경우에는 논블로킹 모드로 동작해야 하고,
모든 요청도 비순차적으로 처리해야 한다. 그렇지 않으면 하나의 클라이언트 요청을 처리하기 전까지
다른 클라이언트의 요청을 처리할 수 없는 상황이 발생한다.
그래서 어떤 모델을 사용해야 하는가?
클라이언트 수가 정해져있다거나 작다면 클라이언트 하나당 스레드를 하나 할당해도 된다.
하지만 1만개의 클라이언트를 처리하려면 1만개의 스레드를 만들어야 한다 😅
1만개를 생성하고 유지하는데에는 큰 성능 저하가 따라오게 되기 때문에
클라이언트가 많아질수록 논블로킹 방식과 비순차방식이 필수가 된다.
가장 이상적인 구조는 아래와 같다.
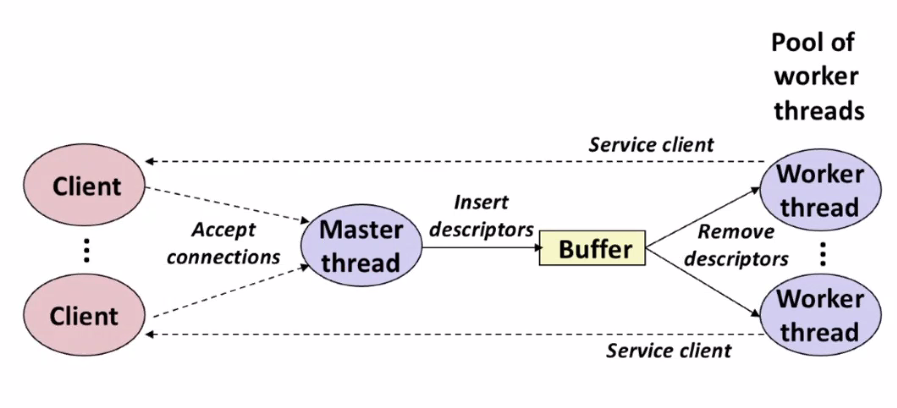
이상적인 구조는 알겠는데 그럼 이런 구조는 어떻게 만들 수 있을까?
해답은 학교다닐때 뭔지 하나도 모르겠던 시스템 프로그래밍과 운영체제 수업시간에 배운
커널 API를 사용하는것이다.
운영체제에서 제공하는 I/O 모델
리눅스 select, poll
20세기말 리눅스 네트워크 I/O모델은 select()과 poll()이 전부였다.
select은 클라이언트 1024개만 처리 가능했고, poll의 경우 제한은 없었다.
두 모델 모두 이벤트가 발생시 어떤 소켓에서 처리해야 할지 알 수 없어
소켓들을 모두 풀스캔해야하는 이슈가 있었고, 또한 가장 큰 fd 번호에 따라
처리 속도 이슈가 있었다.
int select(int nfds, fd_set *restrict readfds,
fd_set *restrict writefds, fd_set *restrict exceptfds,
struct timeval *restrict timeout);
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
void FD_SET(int fd, fd_set *set);
void FD_ZERO(fd_set *set)
위 코드는 man에서 제공하는 select 함수의 인터페이스인데 첫번째 인자로 받는 nfds는
fd의 가장 큰 번호이다. 가장 큰 번호가 1000이라면 반복문을 1000번을 돌아야 한다
따라서 select, poll 함수를 기반으로 한 서버는 실제로 디스크럽터 개수에 따라
성능차이가 심하다
리눅스 epoll
21세기에는 select과 poll을 보완하기 위해 새로운 epoll이 제안되었다.
이벤트가 발생한 시점에 이벤트가 ㅂ라생한 소켓과 종류를 구분할 수 있기 때문에 디스크럽터가 늘어나도 성능차이가 없다.
그렇다고 항상 epoll을 사용하는것은 아니다.
epoll은 성능적으로 우수하지만 제어하는데 많은 코드와 비용이 필요하기 때문에,
적은 클라이언트를 처리할때는 poll이 유용할 수 있다
두 모델의 동작 방식이 다름을 이해하는게 중요하다.
CPU 자원이 넉넉한 지금 이런 것까지 고민해야 하나 싶지만
생산성이라는 관점에선 쉬운길을 두고 어려운길을 택하는건 어리석다고 본다. 😎
윈도우 IOCP
C10k 문제가 등장했을때 당시 윈도우에는 epoll과 비슷한 IOCP가 존재하고 있었다.
1995년 window nt3.5
epoll과 같이 실시간신호 처리를 지원하기때문에 문제를 해결하기 충분했고 지금도 많이 사용중이다.
IOCP는 I/O 요청을 처리할 때마다 버퍼 메모리를 넘겨주지만 운영체제는 넘겨준 버퍼 메모리가 페이징 되지 않도록 잠금을 거는데
이 잠금 수행에 CPU 자원을 많이 소모하게 되는 단점이 있다.
이를 개선하기위해 RIO가 나타났다.
언어에서 제공하는 I/O 모델
리눅스와 윈도우에서 제공하는 커널 API를 사용하면 처음으로 봤던 이상적인 구조를 만들어낼 수 있다
하지만 내가 사용하는 언어가 C 또는 C++이 아니라면 생각만으로도 아찔하다 🤪🥶😱🤮
정말 다행스럽게도 언어별로 커널 API를 포장한 라이브러리와 프레임워크가 있다.
따라서 모든 언어에서도 C10K 문제를 해결할 수 있다.
JAVA - NIO, NIO2
자바 초창기 시절 성능은 매우 안좋았다고 한다. 커널 메모리를 JVM으로 복사하면서 ㅂ라생하는 오버헤드와
그 과정에서 사용한 메모리가 GC 되면서 이중으로 성능을 떨어뜨렸다고 한다.
NIO(New IO)는 이런 문제를 해결하기 위한 라이브러리다. 블로킹, 논블로킹 소켓을 모두 지원했다.
하지만 비순차방식은 지원하지 않았다. 따라서 이 문제는 netty와 같은 별도 프레임워크를 사용해 해결해야만 했다.
Java 7 부터 NIO2가 나오면서 비순차적 방식을 지원하게 되었다.
특이한점으로는 NIO는 리눅스에서는 epoll을 기반하지만 윈도우에선 IOCP에선 select을 기반한다. (NIO2는 IOCP 사용함)
NodeJS - libuv
nodejs는 libuv 라이브러리를 기반으로 한다.
libuv는 epoll과 icop 모델을 지원한다.
libuv가 싱글 스레드위에서 동작하기 때문에 멀티 스레드를 사용할 수 없지만, 비순차 방식을 기본적으로 사용하기 때문에
쉽게 C10K 문제를 해결할 수 있다.
결론
1만개의 클라이언트 문제를 해결하기 위한 방법들에 대해서 살펴보았다.
다시 고민해봤을때 이 문제는 아직도 유효한가?
20세기에는 유효한 문제였을 수 있지만 21세기에는 유효하지 않을 수 있다.
그 이유로는 지금은 이전과 달리 컴퓨팅 리소스가 넉넉하다 또한 성능보단 생산성에 치중되어있다,
그리고 가장 큰 이유는 20세기엔 서버 한대로 최대의 효율을 끌어냈다면 지금은 서버 한대로 서비스를 운영하지 않는다.
클라이언트가 늘어나게 되면 그에 따라 서버의 수도 늘리며 운영을 하게 된다.
게다가 서비스 기능에 대한 복잡도가 높아지면서 데이터 베이스 구조도 점점 복잡해지며 외부 API사용 등
기능 로직을 처리하는 I/O시간이 절대적으로 더 커지게 되었다.
쉽게 말해 네트워크 I/O 처리 방식을 2초에서 1초로 단축시킨다 해도 기능 로직이 5초라면 큰 의미가 없다는 점이다.
따라서 내 결론은 내 서버가 얼마나 많은 요청을 받을 수 있는지 보다는
내 서비스가 얼마나 많은 요청을 받아낼 수 있는지, 그리고 그 양을 받아내기 위해 어떤것이 필요한지 아는 것이다.
- 참고
- 이 글은
마소 394호 - 되돌아보는 1만 개의 클라이언트 문제글을 읽고 정리한 글입니다. - 이미지
- https://12bme.tistory.com/231
- https://usage.tistory.com/60
- https://velog.io/@eunjin/OS-%EC%8B%B1%EA%B8%80%EC%8A%A4%EB%A0%88%EB%93%9C-%EB%A9%80%ED%8B%B0%EC%8A%A4%EB%A0%88%EB%93%9C%EC%9D%98-%EC%9D%98%EB%AF%B8
- https://velog.io/@tonyhan18/%EC%8B%9C%EC%8A%A4%ED%85%9C-%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%98%EB%B0%8DSynchronization-Advanced